Cover Photo by James Harrison on Unsplash
In the rapidly evolving Artificial Intelligence landscape, data quality is the lifeblood that fuels the development of accurate and efficient models. However, accessing and acquiring high-quality, diverse, and labeled data can be quite a challenging task.
In this regard, Synthetic Data arises as a highly impactful alternative to overcome these limitations: the original data can be improved or replaced with new artificially generated data that mimics its characteristics while preserving privacy and utility. Its applications rise across several businesses and industries, from telecommunications, energy, banking, insurance, healthcare, and much more.
However, it is crucial to understand that the success of synthetic data relies on the implementation of best practices and strategies to confidently generate new data that meets the business expectations. For that, we need to turn towards the Data-Centric AI paradigm of development, focusing on systemically assessing and improving the quality of our existing data assets.
In this article, we will explore the main strategies for effectively implementing synthetic data in your AI projects.
Best Practices for Synthetic Data Generation
From data understanding to smart synthetic data, YData has been helping organizations become more data-centric and take the most out of their available data. Based on the challenges we’ve faced across distinct use cases, we’ve identified the 4 main steps to be mindful of when launching your synthetic data projects:
1. Conducting an Effective Data Understanding and Data Preparation Process
Before diving into synthetic data generation, it's essential to have a deep understanding of the original data, from its basic characteristics and descriptors to more complex data quality issues that may arise. This involves data profiling, followed by data cleaning, and feature engineering, among other strategies depending on the issues discovered along the process.
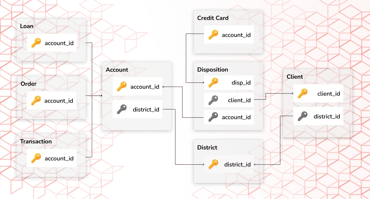
Fabric’s Data Catalog enables a thorough data understanding, which further helps in selecting appropriate synthetic data techniques and ensures that the generated data aligns with the business objectives and expectations.

Fabric's Data Catalog enables a deep data understanding
2. Choosing the Best Synthetic Data Generation Strategy
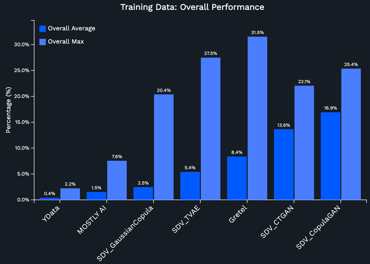
Although wondering what is the best overall solution for synthetic data generation is a common question, there is no one-size-fits-all approach that adjusts seamlessly to all scenarios. The choice of the best strategy ultimately depends on several factors, such as the type of data, its complexity, and the specific task to tackle. Common methods include Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and Bayesian approaches, although finding the best parameters that adapt to the data complexity and scale effectively is extremely challenging.
Fabric selects the best approach given the input dataset, where the generation process is guided by the type of data at hand (tabular and time-series) and its particular behaviors and properties (e.g., missing data, imbalance data, presence of outliers). Additionally, it lets the user control the generation process depending on the end task, where the new data can be optimized for privacy, utility, or fidelity, as we explain in what follows.
3. Evaluating Synthetic Data Along the Essential Standards (Privacy, Utility, and Fidelity)
The process of synthetic data generation involves a delicate balance between privacy, utility, and fidelity. Privacy is essential to protect sensitive information, utility ensures the synthetic data serves its intended purpose, and fidelity guarantees that the synthetic data accurately represents the real data characteristics. This evaluation is also dependent on the specific task to which the synthetic data will be applied and a suitable trade-off is hard, requiring rigorous testing and validation.
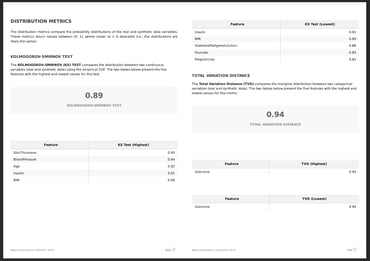
Fabric enables the user to tailor the generation to the required standards, providing a PDF report that evaluates the quality of the new synthetic data using a comprehensive set of metrics and statistics. This helps organizations trust in the accuracy and usefulness of the generated data.
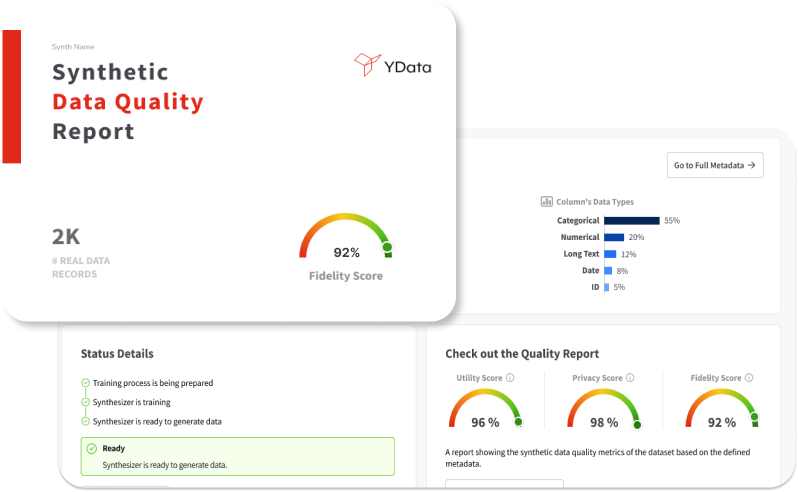
Fabric's Synthetic Data Quality Report enables users to trust the accuracy of the generated data
4. Continuously Assessing and Adjusting the Synthesization Process
Synthetic data generation isn't a one-time endeavor, it’s an iterative process that requires continuous evaluation and adjustment. As your AI models evolve and the real data distribution changes, the synthetic data needs to be adjusted to reflect the new business rules and requirements.
Regularly updating and refining your synthetic data generation pipeline to ensure that it remains aligned with the current state of your data is essential to maintain the performance and relevance of your solutions over time. When assessing changes and experimenting with different data preparation solutions, Fabric's Pipelines are ideal to build, version, and iterate your flows.
Conclusion
There is no doubt about the potential of synthetic data to facilitate data sharing and accelerate AI development. However, it's essential to recall the challenges and trade-offs associated with it generation process. These include a delicate balance between handling the data complexity associated with real-world data, defining suitable and effective models, and complying with business objectives and outcomes.
Successful synthetic data generation requires a deep understanding of the original data, a strategic choice of methods, rigorous evaluation across multiple standards, and an ongoing commitment to monitoring and adjustment. By implementing these strategies effectively, you can harness the power of synthetic data to supercharge your projects while navigating the complex landscape of AI data acquisition.
Unlock the potential of your data with Fabric Community Version or contact us for trial access to the full platform and start generating synthetic data that aligns with your business goals in a seamless and effortless way.