As proven time and again, data quality is key for high-performance results, which means that in order to extract real value out of their ML efforts, organizations need to incorporate data-centric solutions into their machine-learning pipelines.
Much of the effort of the last decades has been put into developing and tuning models, but there is one thing not even the best MLOps tools can help you achieve: actionable, high-quality data.
To help organizations extract the full value of their ML investments, we’re excited to share a new integration between YData Fabric and Vertex AI.
On one end, YData Fabric aims to ensure high-quality data to successfully develop machine learning models. As the first AI platform for data quality, Fabric lets you optimize your data preparation pipelines by providing a set of tools that turn raw data into smart data, namely through data profiling and synthetic data generation, both for tabular and time-series data. In turn, Vertex AI focuses on the model side, aiming to simplify the development and deployment of ML models, namely through AutoML.
In a way, YData Fabric operates on the data-centric paradigm within the DataPrepOps space, whereas Vertex AI operates significantly in the model-centric paradigm, on the MLOps landscape. Needless to say that combining the two will not only accelerate your AI development but significantly improve the value and performance of the ML models put in production environments.
How can Fabric and Vertex AI work together?
Throughout this blog post, we will showcase how both platforms can work together to produce a complete flow, from reading the data to deploying the model into production and making predictions “in the wild”.
To explain the integration, we’ll use Kaggle’s Credit Card Fraud dataset and showcase how the platforms work seamlessly together, improving the quality or the original data, training a machine learning mode, and finally deploying it to production. All the code samples are available in our Academy GitHub repository.
Improving Data Quality with YData Fabric
First, we start by importing necessary packages and loading the data:
This dataset is an interesting example because it incorporates one of the killer data characteristics that jeopardize ML models: imbalanced data. Essentially, whereas the “legitimate” events are abundant, “fraudulent” transactions are rare. This causes ML models to be biased towards legitimate events and fail to classify the fraudulent ones.
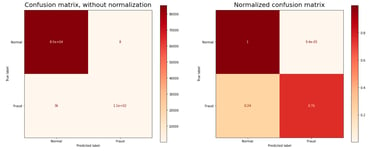
Through the profiling, we can determine that the dataset is highly imbalanced, and it is likely that our performance results will be biased towards the most represented class:
To overcome the imbalance nature of the data, we will use synthetic data to improve the representation of our fraudulent cases:
After boosting the training data with more synthetic samples that represent fraudulent transactions, our classifier is able to better learn the characteristics and data distributions of this concept, which increases its rate of detection:
Now that we are comfortable with the results provided by the model, we can confidently save it to later deploy it to production with Vertex AI!
Deploying a Model to Production with Vertex AI
Using the Vertex AI SDK for Python, deploying your models to production directly in YData Fabric is an easy and hassle-free process.
After you’ve created a Cloud Platform project and set up your authentication credentials, you need to install the Vertex AI SDK and enable the Vertex AI API as follows:
Then, all you have to do is upload the model you’ve created in Fabric through the Cloud Platform:
In this case, we’re leveraging a prebuilt container provided by Vertex AI, but you can also build your own custom containers. After the model is uploaded to Vertex AI, we can finally deploy it to an endpoint:
From there we can get predictions for the test data:
Get started with Fabric and Vertex AI
The path to develop ML solutions that actually work is to go data-centric: models are only as good as the data they were trained on. But then again, they’re useless if not deployed rapidly and efficiently into production.
When used together, YData Fabric and Vertex AI can help you manage an entire data-centric process that will make both your team’s productivity and business results skyrocket.
Along this blog post, we’ve showcased how the integration can be done in a seamless way, all without leaving Fabric’s development environment. You can now follow up on the integration using the materials in our Academy repository and implement your own workflows!
We challenge you to try the full capabilities of YData Fabric and learn more about data quality in our Data-Centric AI Community.
Cover Photo by Joshua Sortino on Unsplash