Synthetic data, artificially generated data that mimics real-world data, is a technology that has undergone significant transformation in recent years. Since the dawn of data-driven synthetic data generation with generative models, synthetic data has rapidly expanded in versatility and application, becoming cornerstone in fields that range from healthcare to finance. Synthetic data ability to replicate complex patterns and distributions found in real datasets, makes it nor only a powerful tool for privacy-preserving use-cases but also as a booster to train AI models.
It is possible to find both open-source and proprietary solutions for the generation of synthetic data in the market today. Both offer diverse capabilities, that vary in quality, usability, and performance, including scalability and speed. For that reason, and with the growing adoption of synthetic data solutions, understanding the pros and cons of each vendor through independent benchmarking (bias free) is essential. In this blogpost, we will be exploring not only the significance of synthetic data benchmarking for single-table and multi-table synthetic data generation, but also the insights from recent reports by Vincent Granville and Rajiv Iyer, two freelance consultants in the field without affiliation with the vendors featured in the report.
The Significance of Independent Benchmarking
Bias-free benchmarks are crucial when assessing new products or adopting a new technology because they provide objective, standardized evaluations of performance, quality, and usability. They allow businesses to compare different solutions on a level playing field, highlighting strengths and weaknesses. Independent benchmarks ensure that decisions are based on reliable data rather than marketing claims, reducing risks and fostering confidence in the chosen solution. They also promote continuous improvement and innovation by setting clear performance standards and expectations and offer unbiased assessments free from vendor influence. This objectivity is vital in evaluating complex solutions, such as AI and/or synthetic data generation, ensuring that the solutions deliver on their promises while meeting the industry standards.
In a nutshell, independent benchmarking provides:
- Unbiased Evaluation: Independent benchmarks provide an unbiased evaluation, free from vendor influence, ensuring credibility and trustworthiness.
- Comprehensive Analysis: These benchmarks offer a thorough analysis of vendor performance, considering multiple metrics and real-world scenarios.
- Industry Standards: Establishing benchmarks helps set industry standards, promoting consistency and quality across synthetic data solutions.
Synthetic data quality benchmark
Synthetic data generation methods and vendors
Synthetic data generation can be achieved through different types of methods and algorithms, such as Generative Adversarial Networks (GANs), Variational Auto Encoders (VAEs), Copulas, Transformers and many more generative techniques.
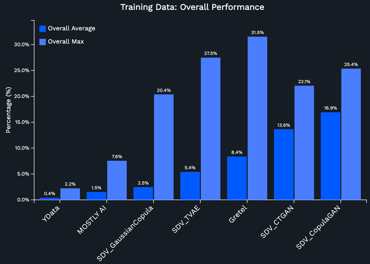
For this benchmark, the authors considered the following synthetic data generation solutions: SDV (Datacebo), MostlyAI, Gretel and YData Fabric.
Independent Benchmarking: Case Studies
Single-Table Synthetic Data Generation
In the benchmark for single-table datasets, several datasets were used. These datasets included applications in fintech, insurance, supply chain, and healthcare.
- Credit Card Fraud Detection: This case study focused on generating synthetic data for a credit card fraud detection dataset. The evaluation considered data integrity, ease of use, and faithfulness to real data patterns. YData Fabric outperformed other vendors by maintaining data integrity and accurately replicating the distribution of fraud and non-fraud transactions, which is crucial for effective model training.
- Healthcare Patient Records: This study examined the generation of synthetic patient records for a healthcare dataset. Key evaluation metrics included data integrity, preservation of patient privacy, and the ability to maintain the distribution of patient demographics and medical conditions. YData Fabric excelled in producing high-quality synthetic data that adhered to strict privacy standards while preserving the statistical properties of the original dataset, outperforming all other products in the comparison.
You can find the full benchmark - methodologies, datasets and metrics in this link.
Multi-Table Synthetic Data Generation
In the second benchmark, it was assessed the capabilities for multi-table synthetic data generation, a synthetic data process with added complexity and unique challenges involved due to the relations between tables. You will find detailed results for the following databases:
-
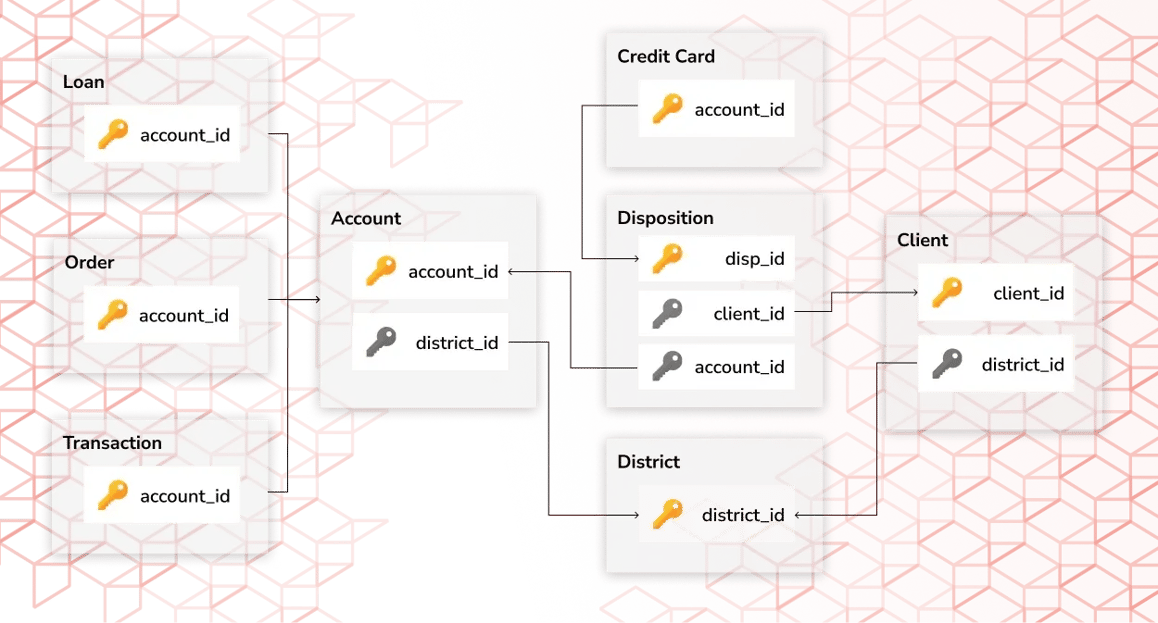
Berka Database: financial dataset featuring multi-table structure with detailed records of bank transactions, client information, loans, and account balances. It is widely used for evaluating synthetic data generation due to its complexity and real-world financial data representation. YData Fabric is the only solution able to capture the double periodicity (monthly and semester) observed for the volume of transactions.
-
AdventureWorks Database: Known for its complexity, the AdventureWorks database includes multiple related tables with timestamped data. YData Fabric was the only vendor to successfully complete the synthetic data generation process while maintaining database integrity, showcasing its robustness in handling multi-table datasets.
-
MovieLens Database: The MovieLens dataset, commonly used in recommendation systems, was included to evaluate the preservation of user-item interactions. YData Fabric demonstrated superior performance in generating synthetic data that maintained the integrity of user preferences and movie ratings.
You can find the full benchmark - methodologies, datasets and metrics in this link.
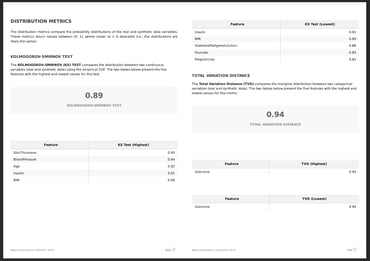
Evaluation Metrics
To ensure a fair comparison between the different solutions it is imperative to define the set of metrics that will be used to validate the quality of the synthetic data generation, as well as the parameters and configurations to be used. In this particular benchmark, all the synthetic data generation methods were used with the default parameters.
Metrics to measure synthetic data quality typically include statistical similarity measures, such as distribution alignment and correlation preservation, which assess how closely synthetic data matches real data. Common metrics also evaluate data integrity, feature relationships, and consistency. Depending on whether the data is tabular or multi-table, the selected metrics account for the data's structure and nature, ensuring accurate reflection of the original dataset's characteristics and dependencies.
Why vendor comparison matters?
Vendor comparison is essential for several reasons:
- Informed Decision-Making: Businesses can select the best synthetic data solution tailored to their needs.
- Transparency: Independent evaluations ensure transparency, highlighting how different vendors perform under various conditions.
- Innovation and Improvement: Regular benchmarking pushes vendors to innovate and improve their offerings, benefiting the entire industry.
Conclusion
Synthetic data has evolved into versatile and powerful technology, essential for privacy-preserving applications and boosting AI model training. With the diverse capabilities of open-source and vendor-based solutions, understanding the quality and performance of these synthetic data generation tools is crucial. Independent benchmarking provides the necessary transparency, allowing organizations to make informed decisions based on objective, standardized evaluations. These benchmarks highlight strengths and weaknesses, fostering trust, innovation, and continuous improvement in the synthetic data market.
We encourage you to explore the detailed benchmarks and reproduce the results yourself at ydata.ai/register.