Cover Photo by Christina @ wocintechchat.com on Unsplash
Coined by Andrew Ng in 2021, the concept of “Data-Centric AI” has taken both academia and industry by storm. It has given rise to hundreds of research publications, fostered the creation of special tracks and colloquiums in the most renowned AI conferences worldwide, and is slowly but surely setting itself as the industry standard across all AI endeavors.
Yet, as all that is new, it still raises a series of questions and a certain skepticism, as a lot of people are unsure about the “internal workings” of this new paradigm and in what ways it is revolutionary for ML advancement. In this article, we’ll cover the fundamentals of Data-Centric AI, the main tasks that fall into this paradigm, and how DataPrepOps is key to implementing Data-Centric AI principles in real-world domains. From theory to practice, one might say.
What drove the need to shift towards a Data-Centric paradigm?
First, we might want to ask ourselves: “Where did it shift from?”. In other words, “What was our main concern before Data-Centric AI?”. Models.
Throughout the past decade, great achievements in AI were driven by researchers wanting to do better on their models: devising new architectures, tuning hyperparameters, conceiving faster, more flexible, and more robust solutions... for the same, static, unchanged, often “quasi-raw” sets of data.
This was inevitably the result of amazing breakthroughs in computational power and resources that ultimately led to the “new advent” of deep learning technologies. Our eyes turned to the possibilities these achievements brought to the development of more powerful models and processing tools while forsaking the fundamental role of data in the process.
At some point, we reached our inflection point: no additional gains were coming from model tuning, so we turned to data (and rightfully so!). Yet, after years of neglecting the search for suitable solutions to store and process data and strategies to improve data quality, we were risking another AI winter. Luckily, the community came together to foster the change to a new AI paradigm: Data-Centric AI. In the new Data-Centric AI paradigm, it is the data, rather than the models, that is the pièce de résistance of the data science lifecycle:
The idea that improving the data is fundamental for a successful machine-learning pipeline is not new. The difference here is two-fold. First, improving the data assumes the “leading role” in the process, whereas improving the model was the main concern in the model-centric approach. This does not mean that models are static or “forgotten” in the data-centric paradigm: it means that instead of extensively tuning and adjusting models, efforts mainly go into improving data quality and investigating how different data transformations impact the end results. Secondly, improving the data is seen as an iterative process, not a “box-checking” before model development.
The overall definition of Data-Centric AI could therefore be as follows: "The iterative and continuous process of improving data, moving from raw data to actionable data that maps onto significant insights on the domain."
"Improving data", if we want to dig deeper, also comes in different flavors, from removing inconsistencies and duplicate values, imputing missing data, performing data augmentation, bias mitigation, data relabeling… virtually any task that aims to enhance the quality of the existing data for machine learning purposes.
Whereas finding a high-performing model is a solved problem for most domains, achieving high-quality, smart data is not. We are at last collectively realizing that improving data provides better results than improving the models and that guiding future development through a data-centric lens is what will provide the next big jump in AI innovation.
Naturally, if this concept is still fresh and sometimes misunderstood, the technological framework required to put it in motion (i.e., finding standard, reproducible, and scalable solutions for improving data) is yet another mind-boggling issue. Thankfully, we have some of the best and brightest actively working to trailblaze that path with the introduction of DataPrepOps.
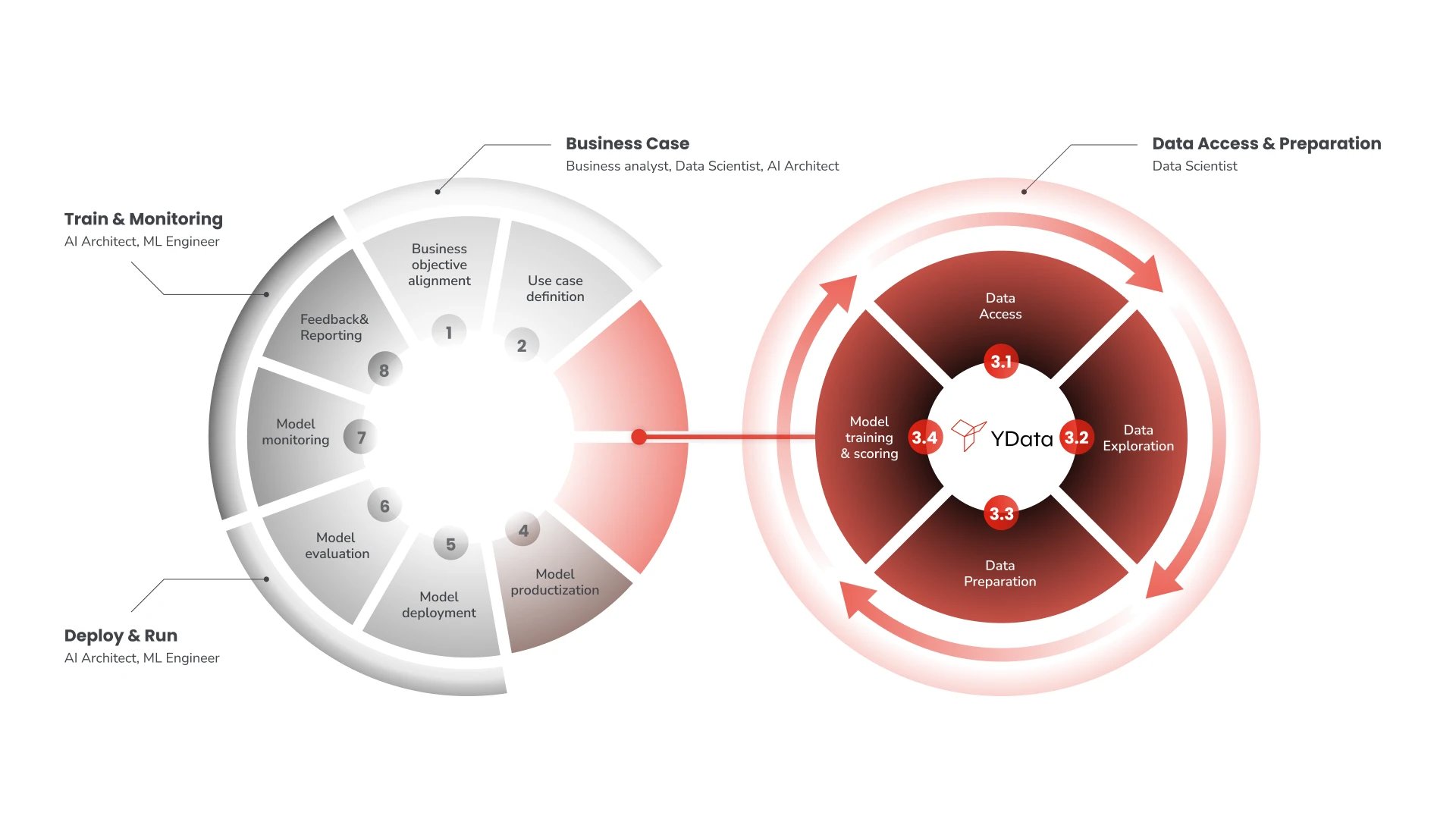
In essence, DataPrepOps operationalizes the steps of data improvement that characterize Data-Centric AI. If you’re familiar with ML development, DataPrepOps, at a high level, is the MLOps of Data-Centric AI, as we explore in what follows.
DataPrepOps: MLOps for Data-Centric AI
What makes "good" data "good"? Can a dataset be "good" for one application and "bad" for another? How are data characteristics related to the choice of a suitable classifier? How is the downstream task (e.g., classification, regression, clustering) impacted by the quality of the data? How can data quality be validated? What features are relevant for this use case? How much data do we need for this application?
As data continuously grows in size and imperfections, answering these questions increases in complexity. Handling imperfect data requires a rethinking of our current practices and standards and the design of well-defined pipelines and suitable automation strategies. Hence, the rise of DataPrepOps.
DataPrepOps emerges as an umbrella term that encompasses all tasks involved in getting data ready for ML production, by defining the appropriate infrastructure, tools, and systems that enable data scientists to adopt a Data-Centric AI paradigm during development cycles.
However, when hearing the words “getting data ready”, most people assume that DataPrepOps is nothing but a standard data preparation step, one that we all are familiar with. Nevertheless, the latter assumes the data as static objects, whereas the former follows the data-centric paradigm of “iteratively and continuously” improving data. So please, do not confuse the Ops!
Oops, I mixed the Ops: DataPrepOps is not DataOps
A concept that commonly enters the mix and has a lot of people confused is “DataOps”.
DataOps focuses on crucial aspects of dealing with data that can naturally lead to higher quality as well. However, the focus is not so much on improving data, but rather on defining best practices regarding its organization, storage, versioning, and security. Here, data is treated as a static element, a bulk of information that needs to be structured swiftly and efficiently, so that it can be accessed and analyzed afterward.
Indeed, DataOps can contribute to improving data quality but it does so at a structural level (e.g., removing inconsistencies or duplicate entries), not from a “data value” perspective.
In turn, DataPrepOps is fully dedicated to increasing data quality and enhancing data value. It operationalizes and automates the process of moving from raw data to high-quality and actionable data, focusing on data-centric operations. As handling real-world data is the perfect setting for human abuse and machine learning bias, DataPrepOps also plays a crucial role in defining and implementing best practices that follow the principles of responsible AI development.
This goes from guaranteeing a complete and accurate data understanding, relying on data profiling and data cleaning, to a thoughtful process of data improvement, frequently carried out via data imputation or data augmentation, a careful data privacy pipeline, for which the current state-of-the-art solution is the use of synthetic data, and a responsible data curation step, involving data filtering, data annotation, and data labeling.
Note that this is a dynamic (and perhaps “never-ending”?) cycle, where raw data is analyzed, improved, and fed to the machine learning models. It becomes clear how this is different from a “one-shot” data preparation step or the “DataOps” concept. The idea is not to support a “one time only” process of curating a training dataset, but rather to understand it as a framework for quasi-real-time tuning of data.
To summarize, we could say that DataOps is detrimental in the Big Data landscape, critical in structuring and storing the data that can later be used in ML development. On the contrary, DataPrepOps paves the way for the Smart Data landscape, incorporating the data-centric paradigm of transforming raw data into quality data (that in fact, does not need to be “big”).
May the Ops be ever in your favor!
As Data-Centric AI takes up more of the spotlight in academia, industry, and market, a lot of new trends and concepts start to emerge. This is natural as AI development evolves, but can lead to some misalignments since we’re facing uncharted ideas every day.
Understanding the key common points and differences between these data-related concepts is a way towards fostering data literacy, promote clear and productive discussions on the topic, and eventually reach a categorization of problems and trends in Data-Centric AI and their best practices, almost as if defining a terminology and standard that can be easily understood by all communities in the AI space.
In this article, we’ve covered the concept of Data-Centric AI and how it differs from the Model-Centric paradigm. Similarly, we’ve clarified how DataPrepOps is the centerpiece of Data-Centric AI, different from a single data preparation stage or the DataOps concept.
In our next article, we’ll distinguish the concepts and scope of MLOps and DataPrepOps in more depth, mapping the DataPrepOps ecosystem in what concerns current tools, platforms, and main players in the space.