Synthetic Data: the future standard for Data Science development
In today’s world where data science is ruling every industry, the most valuable resource for a company are not the machine learning algorithms, but the data itself.
Since the rise of Big Data, a theoretical understanding that data is everywhere has emerged. Nowadays, it’s believed that we are dealing with an amount of around2.5 quintillionsof data available.Sounds great, right?
But, as in any industry, this prime matter needs to be collected and as recent studies show, 12.5% of the time of a data team is lost in tasks related to data collection — up to5 hours per workweek. And, once the data is collected, there is still the need to preprocess it and, eventually, label it.
Giving a practical example — A company in the healthcare sector, developing a model able to analyze Electroencephalographies (EEG) and identify any anomalies, needs tocollect and labeltens of thousands of data points. EEGs are very complex and require highly specialized individuals to label them reliably and accurately. Assuming that labeling asingle patient EEG can take a median of 12.5 minutes, a database with around 12,000 patients, can take up to 2500 hours to be fully labeled.
Knowing the cost per hour of a Neurosurgeon, you can do the math.
This scenario is not only true for the health care sector, but also for many other sectors of the industry. To solve the issues above, a different solution is required — synthetic data — and there are a couple of good reasons behind it:
Prototype Development:Collecting and modeling tremendous amounts of real data is a complicated and tedious process. Generating synthetic data makes data available sooner. Besides that, it can help in faster iteration through the data collections development for ML initiatives.
Edge-case Simulation: It is often seen that the collected data do not contain every possible scenario which affects the model performance negatively. In such cases, we can include those rare scenarios by artificially generating them.
Data Privacy: Synthetic data is a great way to ensure data privacy while being able to share microdata, allowing organizations to share sensitive and personal (synthetic) data without concerns with privacy regulations.Read our previous article Privacy preserving Machine Learning.
. . .
But how can we generate synthetic data? To answer this, I first need to explain what synthetic data is. From the name, we can easily understand that it refers to data that is not collected from the real world but rather generated by a computer. The great benefit of the new techniques for data synthesis is that the resulting data maintains the real-world properties. The methods to generate synthetic data can vary, both on its applications but also on the quality of the generated data.
SMOTE and ADASYN
For a classification task, an imbalanced dataset means the number of examples of one class is very less compared to the others, which harms the learning process. Two of the most known oversampling techniques for minority class are SMOTE and ADASYN.
The most important drawback of sampling methods is related to the fact the these approaches only work on between-class imbalance and not within-class imbalance. Meaning, when it comes to dealing with the bias of an imbalanced learning problem, they do not perform very well.
Imbalanced-learn, a famous Python package dedicated to solve imbalanced datasets issues, includes straightforward and simple to use implementation of the sampling methods.
These networks have usually two components: a graphical structure and a set of conditional probability distributions. Bayesian Networks are typically used for probabilistic inference about one variable in the network given the values of the other variables.
Bayes nets represent data as a probabilistic graph making possible and very easy to simulate new data, synthetic one. Although, very useful for a wide range of use cases, for the generation of synthetic data there are two details that need to be taken into consideration: prior information regarding the dataset is required and Bayes nets can also become quite expensive computationally when dealing with massive and sparse datasets.
Variational Autoencoders (VAE)
VAE are autoencoders whose encodings distributions are regularised and learned during the training process. This type of neural networks attempts to recreate the inputs given severe limitations, while ensuring that the latent encoding space has good properties.
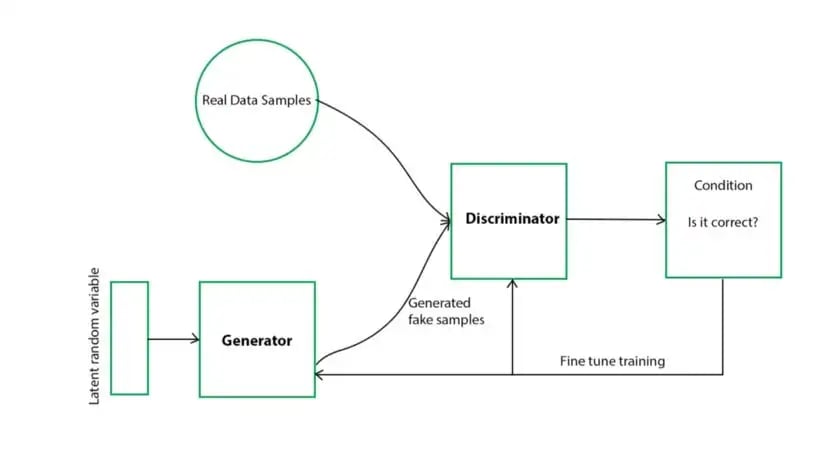
Generically, we can define GANs as models composed by a discriminator and a generator networks that compete with each other during the training process.
GANs aim to learn the true data distribution of the training dataset and try to generate new data points from this distribution with some variations without reproducing the training data. By using this we can produce synthetic records of datasets with multiple classes, which is beyond the scope of traditional models.
Conclusion
Although it’s not a replacement for every single use case where real data is needed, synthetic data has the potential to improve the economics and the chances of success around ML and AI initiatives for most industries.
Under the current reality — COVID-19 pandemics — the need to share patients’ microdata has become even more evident. Sharing microdata while ensuring privacy it’s possible and much needed. The longer we take to make patients’ data widely available the more time it will take until a new diagnosis or even a cure is developed.
Instead of seeing data as a bottleneck, consider synthetic data as a vehicle that will allow your data teams to move faster and become more efficient while prototyping, testing and iterating your business ML-based applications.