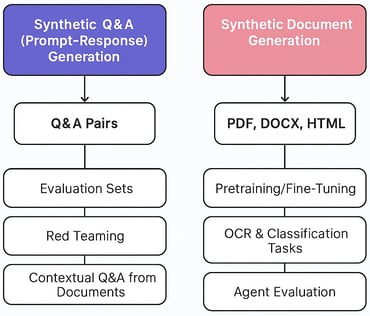
Synthetic Q&A and Document Generation for LLM workflows
As generative AI reshapes industries, the quality, diversity, and safety of the data used to train and evaluate models have never been more critical. Today, we’re thrilled to announce two major additions to YData's product portfolio that...