In today's data-driven world, privacy concerns have become paramount. The use of personal data in various applications raises ethical and legal questions, prompting the need for privacy-preserving techniques. Differential privacy has emerged as a powerful tool to ensure data privacy while enabling data analysis.
In this article, we will explore the concept of differential privacy and how it can be leveraged to provide users with control over the privacy of synthetic data. We will also present a step-by-step tutorial using YData Fabric as well as YData SDK to synthesize data with privacy control.
Understanding Differential Privacy
Differential privacy is a mathematical framework that aims to protect the privacy of individuals' data in a dataset while still providing valuable insights for analysis. The core idea is to add carefully calibrated noise to the dataset to make it difficult to determine if a specific individual's data is present. The noise is introduced in a manner that preserves the statistical properties of the data, allowing meaningful analysis while safeguarding individual privacy. You can check more about Differential Privacy in the podcast when Machine Learning Meets privacy presented in partnership with the MLOps Community.
Why combine Synthetic data with Differential Privacy?
Combining synthetic data with differential privacy offers a powerful approach to address the challenge of data privacy while maintaining data utility. The use of synthetic privacy guarantees can be enhanced when combined with privacy-enhancing technologies such as Differential Privacy, as certain statistical properties of the original data may still be vulnerable to re-identification attacks. It mainly depends on the size and structure of the datasets being explored.
Differential privacy, on the other hand, and although it provides measurable privacy guarantee, it not always yield useful data for analysis due to the added noise. But let's analyse the benefits of this measure in more depth:
- Enhanced privacy protection: Differential privacy, depending on the available data, can ensure safeguards to individual data in a dataset, even from adversaries with extra information. To minimize privacy breaches and re-identification, adding noise during data synthesis is crucial. This is particular useful for smaller datasets.
- Ensured data utility: Synthetic data generation aims to create data that preserves statistical characteristics without real individual information. Differential privacy balances privacy and data utility for useful synthetic data.
- Legal and Ethical Compliance: Data privacy regulations in various jurisdictions have stringent rules regarding the use and sharing of personal data. To comply with these regulations and ensure ethical data handling practices, organizations can utilize a combination of differential privacy and synthetic data. This approach reduces legal liabilities.
- Privacy Tuning: Differential privacy provides a customizable level of privacy protection through a parameter known as epsilon. This parameter can be adjusted by data users to meet their specific privacy needs and requirements.
Fabric for Synthetic Data synthesis with Privacy Control
Fabric provides a comprehensive set of tools to generate synthetic data with fine-grained control over the privacy parameters. It offers an implementation of differential privacy mechanisms, empowering users to customize the level of privacy translated into levels that are easy to adopt and understand from a business perspective. The synthesis experience accomplished both through the UI or programmatically.
For the purpose of today's blog let's deep dive on a step-by-step tutorial to demonstrate how to synthesize data with privacy control through the UI interface.
Tutorial: Synthesizing Data with Differential Privacy through a Privacy Control
To get started, ensure that you have your datasource already created. You can check how to create a datasource in this blogpost. After selecting your dataset that we want to synthesize, a menu with the steps for the synthesizer configuration is shown:
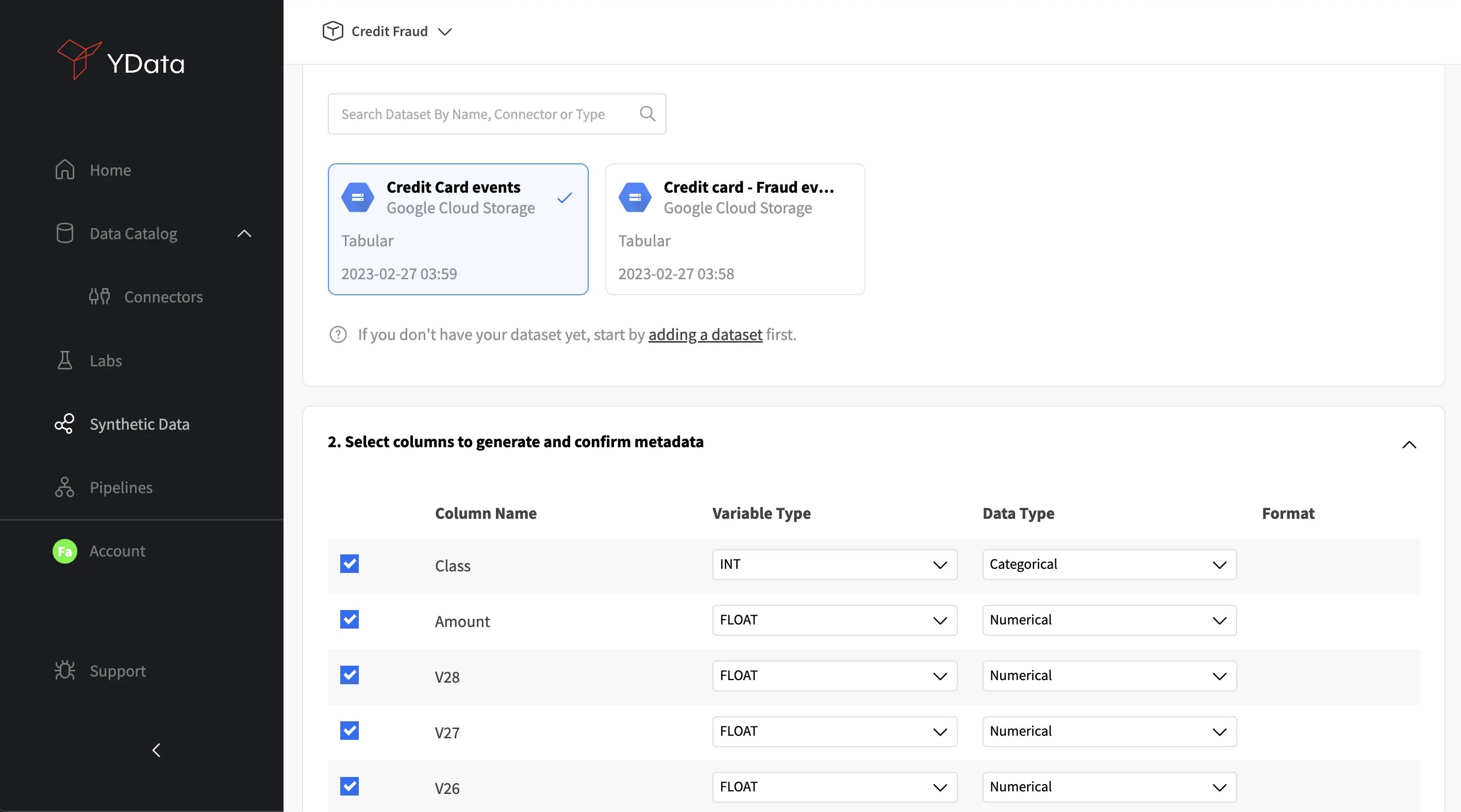
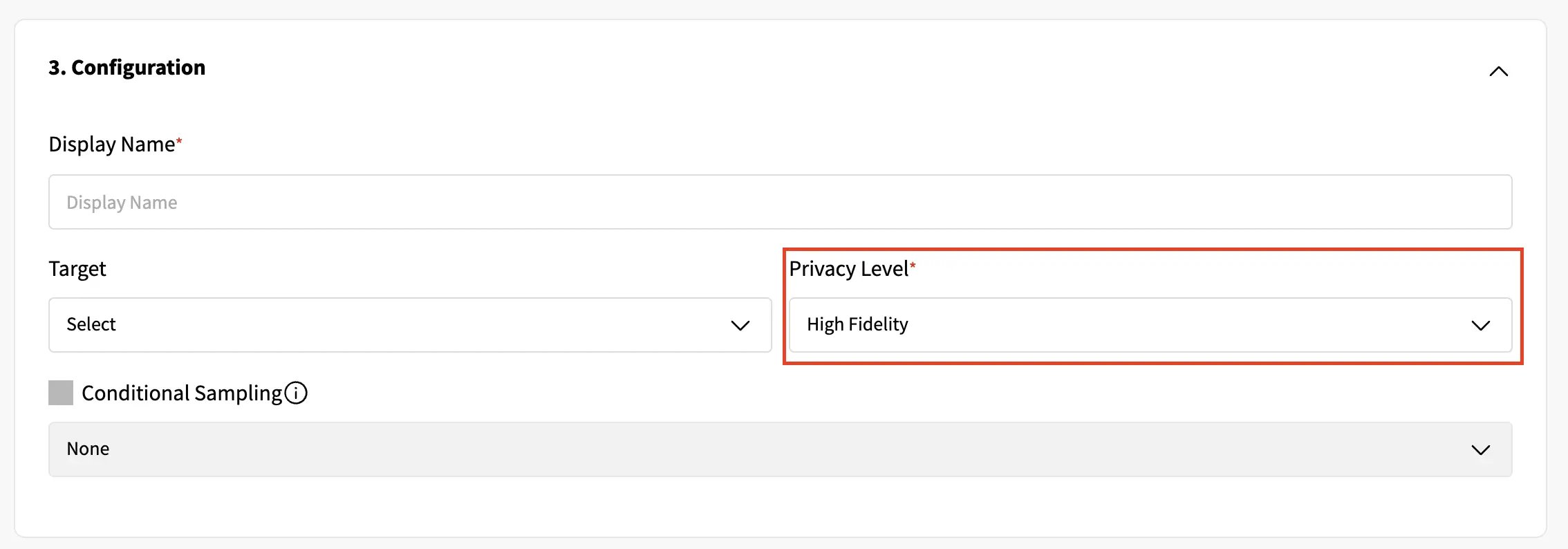
After checking my dataset metadata configurations, I can choose some of my synthesizer parameters, such as the Conditional Synthetic Data Generation (read more about it in our last blog post) and the privacy parameter. For the privacy parameter 3 settings can be found:
- High fidelity (default): the model is optimized targeting the utility and fidelity of the dataset. This is usually the recommend option as it keeps all the statistical properties of the synthetic set closer to the ones observed in original data. For datasets with a large number or rows, this option is usually also aligned with the needs of minimizing re-identification!
- Balanced: the model is optimized to achieve an optimal trade-off between privacy and fidelity for the synthesization;
- High privacy: the model is optimized to reduce the risk of re-identification of an event/observation. This is ensure by adding more noise into the process. Usually recommend for smaller sets of data.
In this tutorial we've selected the "High Fidelity" option.
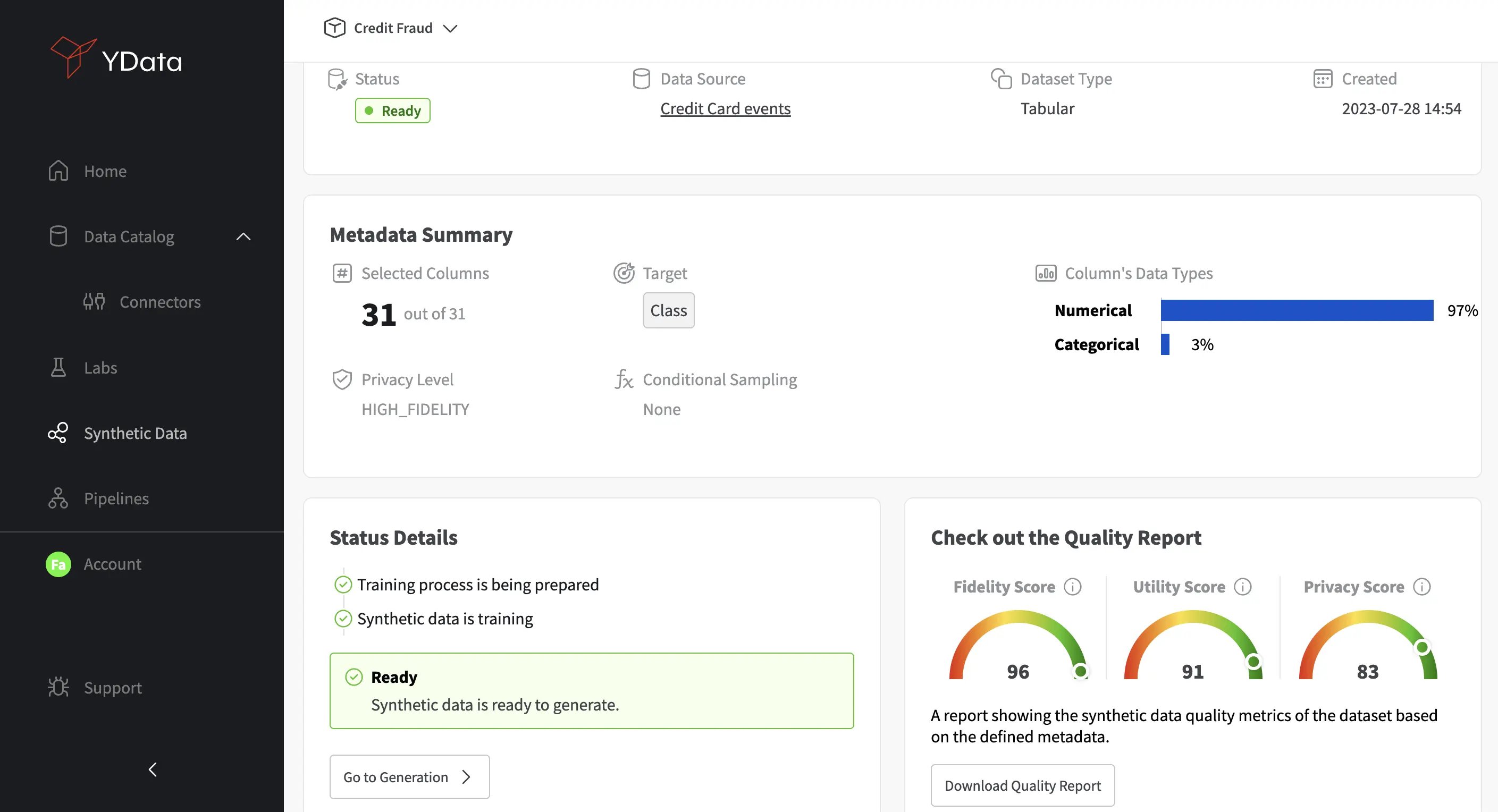
After the synthesizer is successfully trained, you'll have access to synthetic data quality metrics in 3 main areas: Privacy, Utility and Fidelity. Evaluate the privacy and utility of the synthetic data to ensure that the privacy configuration that you have chosen strike the appropriate balance between privacy protection and data utility while aligned with your use case!
Conclusion
Differential Privacy has emerged as an important technique to protect individuals' privacy while enabling meaningful analysis and development of Machine Learning solutions. Synthetic data, generated with Fabric and with the selection of privacy controls, empowers users to balance privacy and utility effectively and more aligned with the business needs and expectations!
As the demand for privacy-preserving methods increases, leveraging differential privacy and synthetic data becomes essential for organizations and researchers to ethically and securely analyze sensitive data.
Take charge of data privacy and data-driven insights with Fabric and register in our community version!
If you want to know more about the benefits of privacy controls and synthetic data generation, contact us, our experts will be delighted to guide you!
Cover Photo by Dayne Topkin on Unsplash



