An odyssey on improving data quality with synthetic data and model delivery with MLOps
Machine Learning and AI are two concepts that definitely have changed our way of thinking in the last decade, and will probably change even more in the next few years. But, we are also aware of the cliché when talking about Machine Learning —“Garbage in, garbage out”. This is undeniably true, the key factor of AI solutions is continuous improvement with the right data, at the right time.
Sounds easy, right?But, what if I told you that there are still many challenges around getting the right data at the right time, and make this a continuous reality? Especially when bringing your data-driven applications to production.
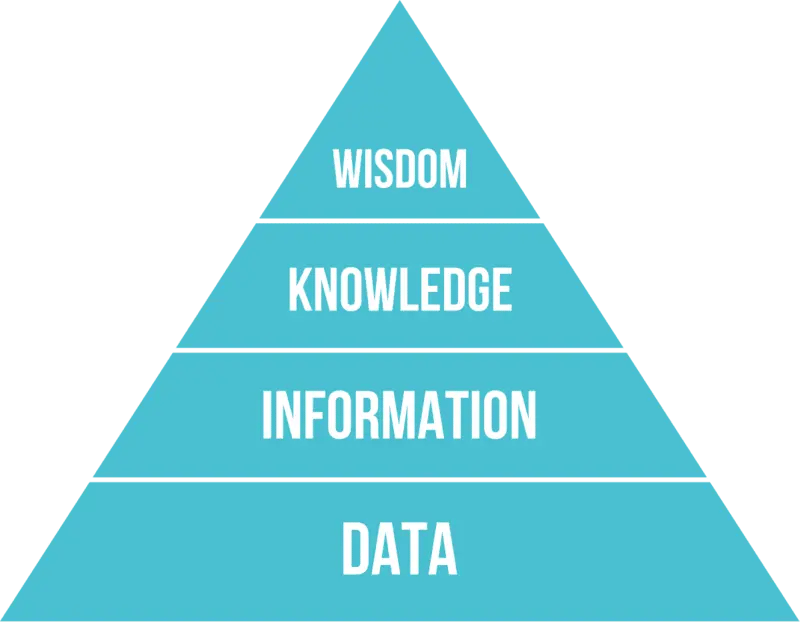
Let’s start with the basics,data qualitycan be defined as how data is accurate, complete, consistent, reliable, and above all, up to date. Data is foundational, as depicted in the good and old DIKW pyramid as per the below image, and particularly impactful in Machine Learning based projects — if we have no good data, then we can’t have good information.
Utterly, understanding the quality of data promptly can “make it or break it” when it comes to data science projects.
At YData, data quality for data science teams is taken very seriously. So seriously, that YData built a whole platform around this concept. It goes from accessing data to exploration and processing, being synthetic data generation one of the core features.
Synthetic datacan be a powerful ally to help organizations achieve improved data quality.But how?
From its name, we can easily understand that it refers to data that is not collected from the real world but rather generated by a computer. The great benefit of the new techniques for data synthesis is that the resulting data maintains the real-world properties. Synthetic data can be generated using a variety of different methodologies, nevertheless, when talking about high-quality synthetic data, we are looking forgenerated datathat retains the utility, fidelity, and reliability of the real data while remaining privacy-compliant. And that is what is offered with new methodologies such asVariational Autoencodersor Generative Adversarial Nets.
Why synthetic data for improved model training?
Data derived from real-world events have a wide range of applications that help data science teams to improve their existing datasets, reducing access time to relevant and sensitive data and seamlessly mitigate implicit bias problems:
1. Prototype Development:Collecting and modeling tremendous amounts of real data is a complicated and tedious process. Generating synthetic data makes data available sooner. Besides that, it can help in faster iteration through the data collection development for ML initiatives.
2. Edge-case Simulation:It is often seen that the collected data does not contain every possible scenario which affects the model performance negatively. In such cases, we can include those rare scenarios by artificially generating them.
3. Datasets augmentation, bias & fairness:Not all the times we have the required amount of data, or in other cases, we might be dealing with under-representation in some classes. Automated decision-making can make these issues even worse but synthetic data is a great option to mitigate these problems.
4. Data Privacy:Synthetic data is a great way to ensure data privacy while being able to share microdata, allowing organizations to share sensitive and personal (synthetic) data without concerns with privacy regulations.
What is Machine Learning Operations?
Machine Learning Operations (MLOps) is, at its core, a set of processes and best practices to have a reliable infrastructure for running and managing everything Machine Learning related. This results in a predictable, stable, and secure environment. Without MLOps, many Machine Learning algorithms would still be running on the laptop of some data scientist. Not a great way to run your business-critical algorithms.
Well, imagine that you are satisfied with the (local) model performance, and you want to go ahead and make your model operational on your company’s infrastructure (which is maintained by the IT department). However, the model code and the data often undergo different handovers from data science teams to IT and back, before it’s fully deployed in production. This is not only time-consuming, it’s also frustrating and leads to risks such as running out of time and budget or compromising for security. That’s why ideally, the data scientist is not only involved in building the dataset and model training but also in model serving and hosting. Of course, IT must be satisfied with the security and robustness of the process. Iterations are then easily made, changes can be passed on quickly, and the final application can deliver the desired value within the expected time.
UbiOps handles many of these MLOps tasks for you so that you can focus on creating valuable algorithms, while still having them in a professional environment. And without needing any IT expertise.
Some examples of MLOps would be:
1. Scalable serving:Algorithms should be scalable. Demand for your algorithms is often not constant. With scalability, you always have the right amount of resources. Decreasing costs and maintaining speed.
2. Standardization and portability:Having repeatable and expected results is key in any professional environment. In MLOps this boils down to having models in a standard format that can run everywhere and most importantly run the same everywhere.
3. Version control: Reliability has a lot to do with understanding and tracking changes in your project. This, for example, helps with quickly reverting to an older version when a problem occurs. Not only on the source code with for example GIT but also on a serving level with different versions ready to go in case a new version has unexpected problems.
In real-world scenarios, it is very common to bump into very imbalanced datasets. This type of behavior is frequently found in different industries, from financial services to telecommunications or utilities, and for many use cases, such as fraud detection or predictive maintenance. An effective way to enhance the size and quality of datasets with this type of behavior is through data augmentation.
Imagine that, as a data scientist, you have developed an algorithm to detect credit card fraud but due to the available imbalanced dataset you are not satisfied with the results. On top of that, you have all your code running on your laptop, which is not suited for production.
The use of tools such as synthetic data generators, allows you to quickly learn and replicate the patterns from the underrepresented classes. TheYData’s open-source repositoryallows you to explore and experiment with different synthetic data generation methods. Using the ydata-synthetic library you can easily generate synthetic data with just a few lines of code.
When using the ydata-synthetic library you can easily generate synthetic data with a few lines of code:
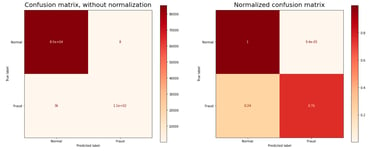
Through the combination of the new synthetic frauds with the real data, you can easily improve the quality and the subsequent accuracy of your classifier. In this example, we achieved good results using a simple WGAN with Gradient Penalty, but there are many parameters to tune and other concerns to be worried about, such as the data dimensionality, the scale of production datasets and the list goes on. That’s what YData’s platform delivers, a way to leverage the latest deep generative data synthesization at scale and optimal for different uses.
Different parameter choices have different results. Source
But the data science lifecycle does not end with the model training and testing. After achieving results that match the business expectations, we need to ship the model to a stable production serving environment and start delivering real value for the end-user.
How to do so without mastering concepts such as containers, Kubernetes, and API development? Happily for us, data scientists, with the rise of MLOps tools such asUbiOps, data scientists are now in control of the full process of not only model development but also delivery and maintenance.
You can reproduce and test this fraud use case easily — YData together with UbiOps has created a notebook and made it available onGitHub. In this notebook you will learn how to 1) create and benefit from synthetic data to mitigate issues related to imbalanced datasets to train and 2) deliver a better model to a production serving environment.
Conclusion
The lifecycle of ML solutions is very complex and hard to ensure not only due to the shortage of data scientists and engineers but also because of the (often) existing technical debt. The impact of data quality on the model’s results is notorious while the challenges to achieve the best and optimal training dataset are already quite big. This makes the preprocessing step one of the most important steps to ensure reliability and standardization.
Nevertheless, data and models only have the expected impact on businesses if models are served into production. MLOps is the key answer to ensure timely, robust, and scalable delivery of models into production.
YData and UbiOps are seamlessly integrated, enabling data science teams to easily improve their existing data and deliver models in a safe and stable production environment.