Modern data development tools and how data quality impacts ML results
ML is all around us! From healthcare to education, it is being applied in many domains that affect our daily activities and it’s able to deliver many benefits.
Data quality carries a very important and significant role in the development of AI solutions — just like the old “Garbage in, garbage out” — we can easily understand the weight of data quality and its potential impact in solutions like cancer detection or autonomous driving systems.
But, paradoxically, data is probably the most undervalued and less hyped of AI. Fortunately, and after a few world-scale and impactful mistakes, the glamour is being returned to data with the rise of data development tools.
Data development
There’s a lot of talking about all the benefits and great things ML can deliver. However, numbers around the struggles that many organizations have to get their return on investment in AI just keep popping.
Are they a lie? Or is there a missing piece in the ML flow that is far more relevant than we thought?
The answer is easy and straightforward: data quality.
Data quality has many different aspects, in particular, data for Machine Learning development has its own quality requirements. There are a lot of new tools emerging in the space of Machine Learning development with a lot of interest around MLOps and how to solve the existing organizational problems to deliver AI successfully into production. But what about data quality?
Data quality can be seen and measured differently at different stages of the flow — data quality in the ML flow starts with the definition of data is required all to the measurement of data drift that can impact models in production, as depicted in the graphic below.
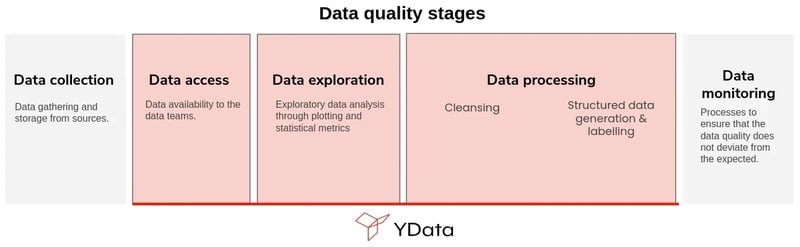
The different data quality stages in the ML flow.
In today’s blog post, we will specifically focus on one of these steps: data preparation.
Data preparation
Although not as sexy as “building” a model, data preparation is one of the most important but also one of the most time-consuming of the data science development process. The time this step consumes for data science teams might vary depending on the company size and vertical, but accordingly to the latest report from Anaconda, is still one of the steps of data science that
“(…) takes valuable time away from real data science work and has a negative impact on overall job satisfaction. (…)”
Data preparation involves many different steps, that goes from data access all the way to feature selection:
-
Data access: the beginning of every data science project starts with the data collection to answer a set of business questions (or at least it should!), but sometimes this process can take a bit more time than expected — either the data does not exist and data engineering processes are required to be set, or there are too many security layers blocking transparent access to the data. Solutions such as differential privacy, synthetic data, and federated learning are viable options to mitigate data access-related issues.
-
Data augmentation: in some cases, the available datasets are too small to feed ML models. Solutions such as data cropping, rotation, windowing, or synthetic data can help.
-
Data cleansing: from missing values imputation to inconsistencies, data is full of errors that need to clean and preprocessed accordingly. Depending on the type of data, this process can be not only time-consuming but also very complex.
-
Data labeling: more often than not, labels are missing from datasets, or the available amount is too small to benefit from supervised learning methods. From rule-based solutions to synthetic data, there are some new options that can help data science teams to have this sorted out.
-
Data validation: how can we ensure what is the quality of the data we are working with? After all the preparation, how can we measure the benefit brought from the applied transformations? A constant measure of the quality of the data throughout the process of development is crucial to optimize the decisions made — from a univariate understanding of the distributions to validating the utility and impact of the data for model development.
-
Feature engineering: the last stage of the data preparation process. This is where the business knowledge also comes in handy, for the process of feature extraction, where the data science teams can definitely shine. After all, the more relevant and impactful the features are for the business, will also impact the downstream models' explainability.
There is a lot to be done at this stage of the ML process, nevertheless, and as pointed out in Workbench’s latest report, a VC firm specialized data companies for Enterprise, data preparation is without a question the missing piece of the many different tools available in the landscape of ML development, and it’s rising with a new name — DataPrepOps.
DataPrepOps is a Data Science and ML engineering culture and practice that includes a set of steps that aims to build a training data set (DataPrep) for ML system operations (Ops).
Conclusion
Now that we are sure and have already experienced the impact that data quality has in ML models, a new paradigm might be surfacing — data development — all because poor data quality can have outsized effects in many different contexts.
The cost of poor data quality, not only affects directly the businesses, especially only detected at a later stage (models developed with bad data are already in production), but also highly affects the productivity and effectiveness of data science teams.
DataPrepOps or data development tools are the missing pieces of the ML development flow. Combined with the right tools from the AI Infrastructure stack, such as features stores and model deployment platforms, data development tools can help organizations use AI as a competitive edge, leveraging their true valuable asset, their data.
Fabiana Clemente, CDO at YData