High-dimensional datasets are at the heart of many business applications and domains, from financial services to telecommunications, retail, and healthcare. These datasets, characterized by a large number of columns — sometimes hundreds or thousands — hold a tremendous potential for valuable insights. However, they also bring forth unique challenges that demand innovative solutions, as we will explain in this article.
Previously, we’ve discussed the challenges that high-dimensional datasets pose to data profiling and how Fabric enables data understanding across several complex domains. Here, we’ll focus on the challenges that datasets with a high number of attributes bring to the process of synthetic data generation and how Fabric can easily overcome them.
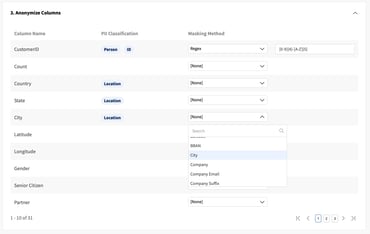
Indeed, several applications that naturally produce high-dimensional data — retail(e.g., user purchases in e-commerce) and healthcare (e.g., clinical trial datasets) are very good examples — require that data privacy is maintained at all times, both for data-sharing initiatives as well as throughout the entire development cycle.
Synthetic data acts as a privacy-enhancing technique, but coping with such a tremendous number of attributes is not an easy task. Unless you’re already leveraging Fabric, of course.
Synthesizing Large Column Datasets with Fabric
Generating synthetic data involves mimicking the characteristics and relationships of real data, which becomes extremely complex and computationally expensive as data dimensionally increases, sometimes reaching thousands of attributes to map.
Fabric is capable of seamlessly accommodating very high-dimensional data allowing users not only to profile these datasets but also, generate new synthetic populations. When it comes to synthetic data generation, Fabric is particularly unique in the synthetic tooling space, with the generation methods being able to cope with large numbers of rows and columns.
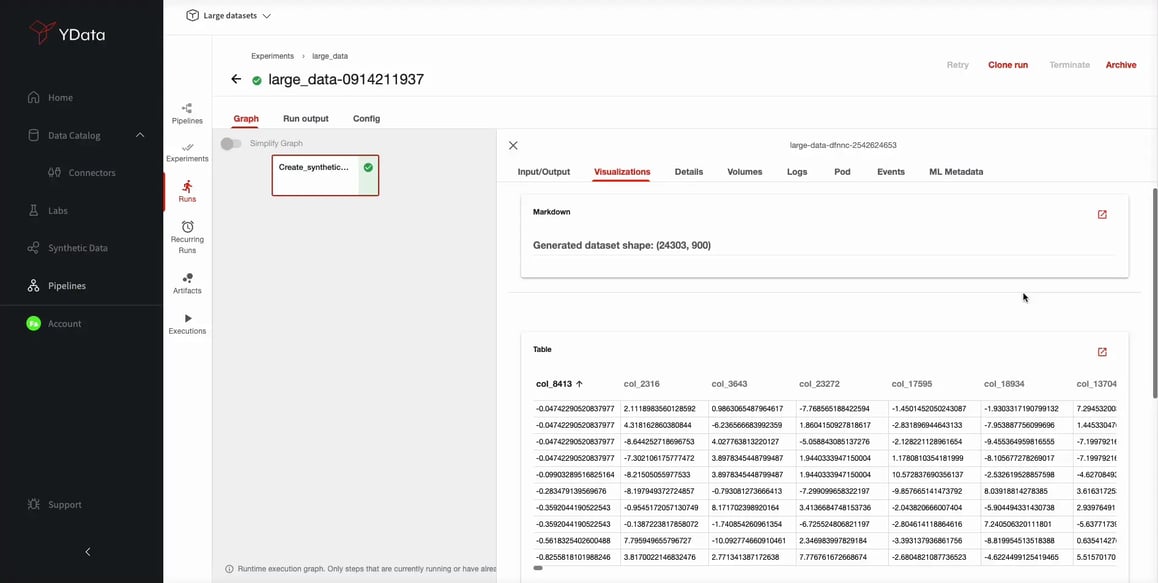
Let’s see a practical example of how Fabric is able to generate synthetic data for a dataset with more than 20K columns!
Generate Synthetic Data with Data Pipelines Orchestration
Datasets with a large number of columns are generally challenging, not only from a computational perspective but also due to the “curse of dimensionality”. After all, datasets with a large number of columns might be challenging when it comes to drawing meaningful insights and patterns.
Metadata Extraction
Fabric’s Synthesizers are able to accurately model the multivariate data distribution in high dimensions, reproducing the existing relationships and interactions of the original data. To ensure the replication of utility and fidelity observed in the original dataset there is a crucial step of the synthesis process – the metadata extraction.
Metadata extraction from datasets, especially large ones with thousands of columns, is a crucial step in understanding and managing data efficiently. The process involves obtaining descriptive or structural information about the dataset's contents in such a way, that the synthetic data maintains real data value, holding its utility even in these complex scenarios.
Synthetic Data Generation & Pipelines for Reproducibility
Our unique process of synthetic data generation is able to efficiently distribute rows and columns for horizontal processing, accommodating datasets ranging from millions to billions of rows, and more impressively supporting those with thousands of columns! The combination with Dask enables our synthesizers to benefit from an elastic infrastructure that is able to adapt depending on the volumes of data to be synthesized.
Furthermore, Fabric Data Pipelines enable the orchestration and reproducibility of scalable synthetic data generation processes. Features like the pipeline scheduler allow a recurrent flow to feed test environments or to automate data sharing with different teams in the organization.
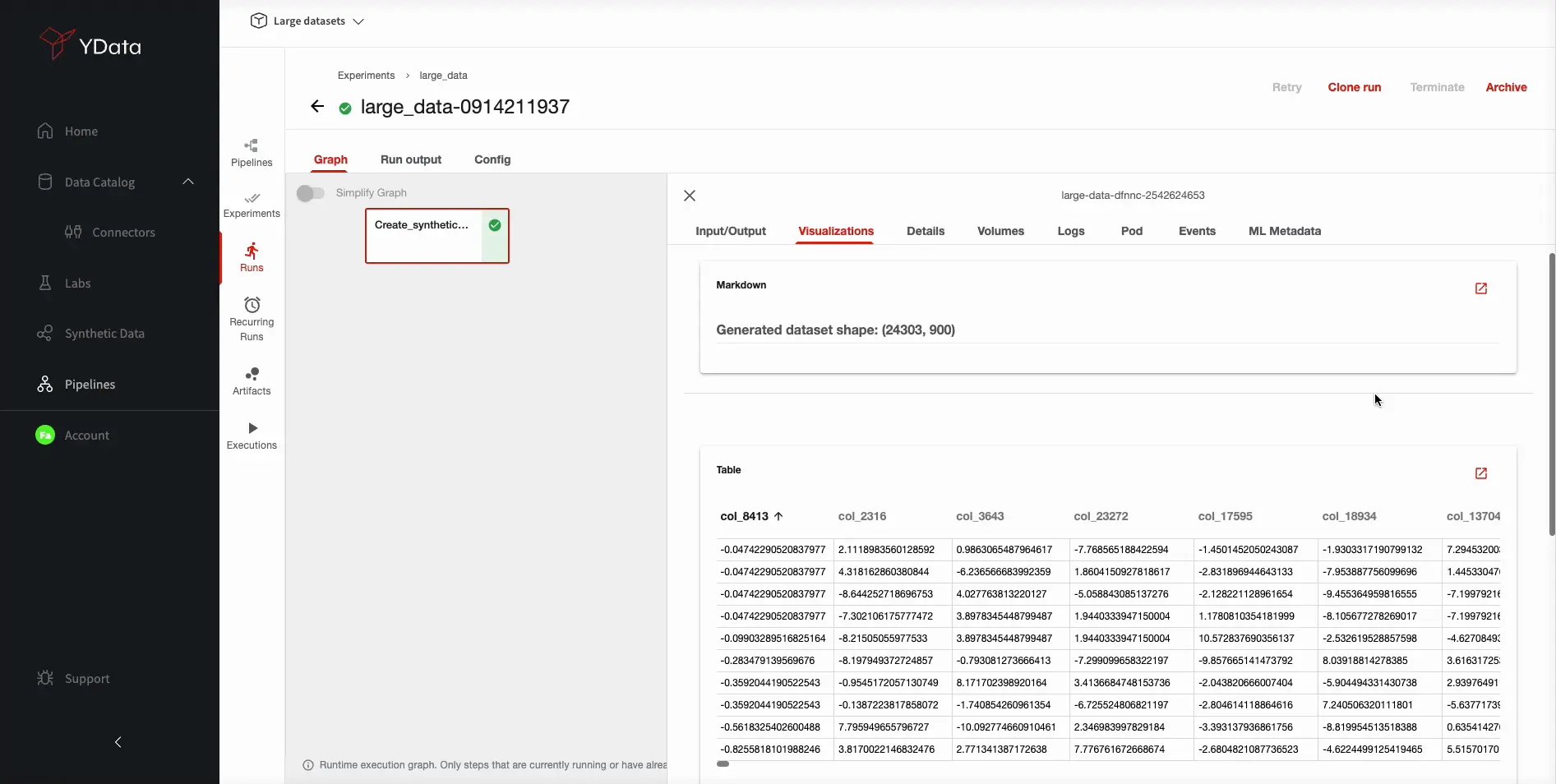
You can see how to create the full flow for data synthesis of a high-dimensional dataset in this video.
Conclusions
With its ability to seamlessly enable the exploration and synthesization of high-dimensional datasets, Fabric’s benefits naturally translate into reduced data preparation and development times and quicker insights, which gives organizations a competitive advantage.
Although large datasets pose a complex challenge to most platforms, Fabric’s patented data flow is able to handle datasets with any number of rows and up to thousands of columns, ensuring adaptability to even the most complex business domains.
If you’d like to try the benefits of Fabric for your large multivariate datasets, sign up for the community version and put it to the test for your organization. You can also contact us for full trial access to the full platform, we’ll be delighted to guide you.