Attending to the current panorama of privacy regulations such as GRPD and CCPA, synthetic data has become an indispensable strategy for organizations looking to unlock their data sharing and development initiatives.
Synthetic data is designed to capture the complex characteristics of the original data, mimicking its behavior. Nevertheless, for some use cases, it is important to replicate the original dataset with all its details, including information such as IDs. The combination of synthetic data with anonymization brings an extra layer of benefits and a reduction of the re-identification risk.
In this article, we’ll discuss why anonymization is an added value for producing realistic privacy-preserving synthetic data and how Fabric enables users to handle sensitive data with automatic identification of Personally Identifiable Information (PII) and masking.
Why combine Anonymization with Synthetic Data Generation?
Since most businesses operate with real client data, organization’s datasets often contain private or sensitive information, often referred to as Personally Identifiable Information (PII). Overall we can consider two types of sensitive information - direct identifiers, such as IDs, social security numbers, etc; and quasi-identifiers, attributes that when combined with others can lead to potential re-identification. You can read more about it in this whitepaper.
Synthetic data is a privacy-enhancing technology that is private by design and for that reason compliant with regulations as there is no one-to-one relation between the real and generated records. But despite synthetic data has proven its value compared to traditional anonymization techniques, there are use cases where users can benefit from the combination of these techniques:
- Enhanced data privacy: The two methods together can ensure that even if synthetic data somehow resembles real data structure, the underlying real data is already anonymized, adding an extra layer of protection. This is particularly useful when designing synthetic data flows for Quality&Assurance (QA) environments, where keeping the same data schema is crucial, including even identifiers.
- Preservation of data utility: Using more synthetic data can lessen the need for data anonymization, making datasets more detailed and accurate. For instance, with synthetic census data, we don't have to group ages or leave out gender.
- Reduction of storage costs: Instead of storing large volumes of real (even if anonymized) data, organizations can generate synthetic data on-demand, leading to potential savings in storage costs.
- Protection against adversarial attacks: Combining traditional anonymization and synthetic data can make it challenging for malicious actors to reverse-engineer or gain insights into the original data, providing an added layer of security.
While each method has its own benefits, a flow where the combination of both is made easy opens the door to new layers of security, privacy, and applications, namely to generate new Quality Assurance environments where keeping the same structure as the original data is relevant or when working with geo-location data in which, depending on the business context, we might want to mask some of the columns.
In the next sections, we’ll discuss how Fabric enables a seamless experience for the generation of privacy-preserving synthetic data, exploring its main functionalities that enable data privacy while keeping the data’s original structure.
How to leverage Fabric to manage PII and combine Synthetic Data with traditional Anonymization?
With the focus on easing the access to data, Fabric offers flows to improve the identification of PII, and a synthetic data generation flow fully integrated with other privacy-enhancing technologies.
To ensure private synthetic data, Fabric incorporates synthetic data generation and anonymization in a single flow to create realistic and privacy-preserving datasets while helping to manage PII:
- Fabric’s Data Catalog offers a feature to automatically detect and flag potential PII during the creation of your data sources;
- During the synthesization process, users can remove or seamlessly mask any column using a wide range of pre-configured options;
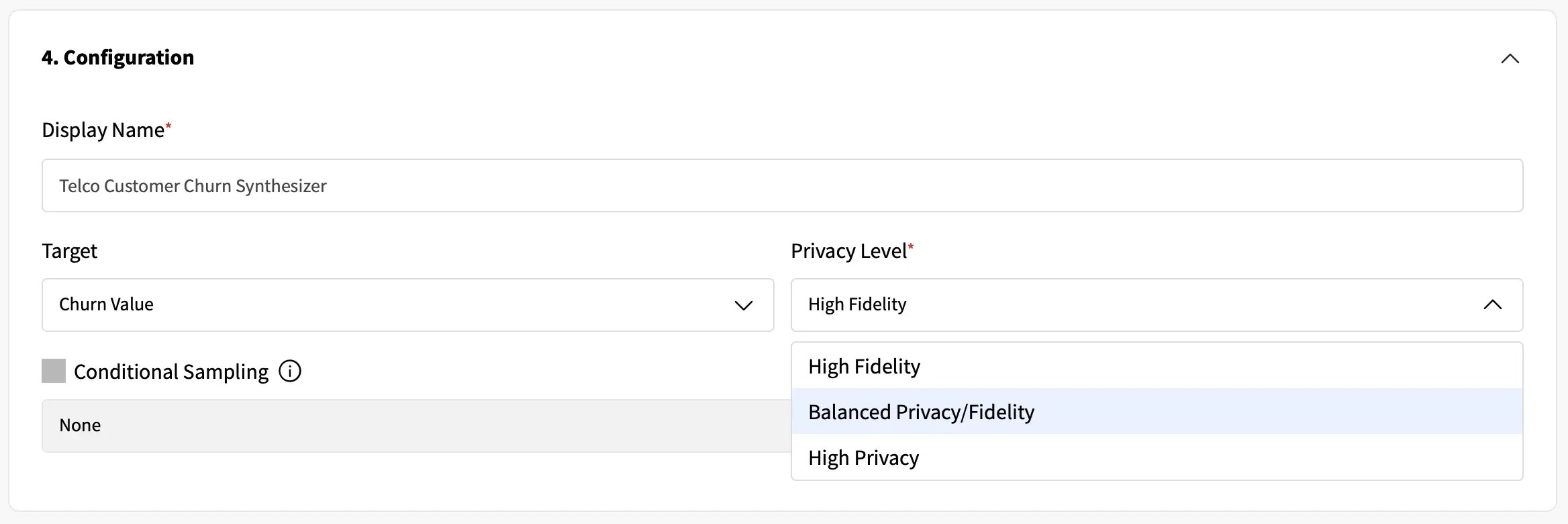
- Fabric further provides fine-grain control for the synthetic data generation, offering differential privacy mechanisms that users can adjust according to different levels of optimization, including high-fidelity, high-privacy, and an optimal trade-off between fidelity and privacy.
Altogether, Fabric provides a holistic approach to data sharing, reducing the risk of re-identification of sensitive data. Using Fabric, users can manage their private datasets in a comprehensive Data Catalog with automatic identification of potential PII, leverage the potential of a private-by-design technology – synthetic data – and combine it with the benefits of more traditional privacy methods, such as anonymization.
In what follows, we will demonstrate how Fabric ensures data privacy throughout the entire cycle of data preparation, from the potential PII detection during profiling to the generation of high-quality synthetic data.
Generating tailored privacy-preserving synthetic data with Fabric
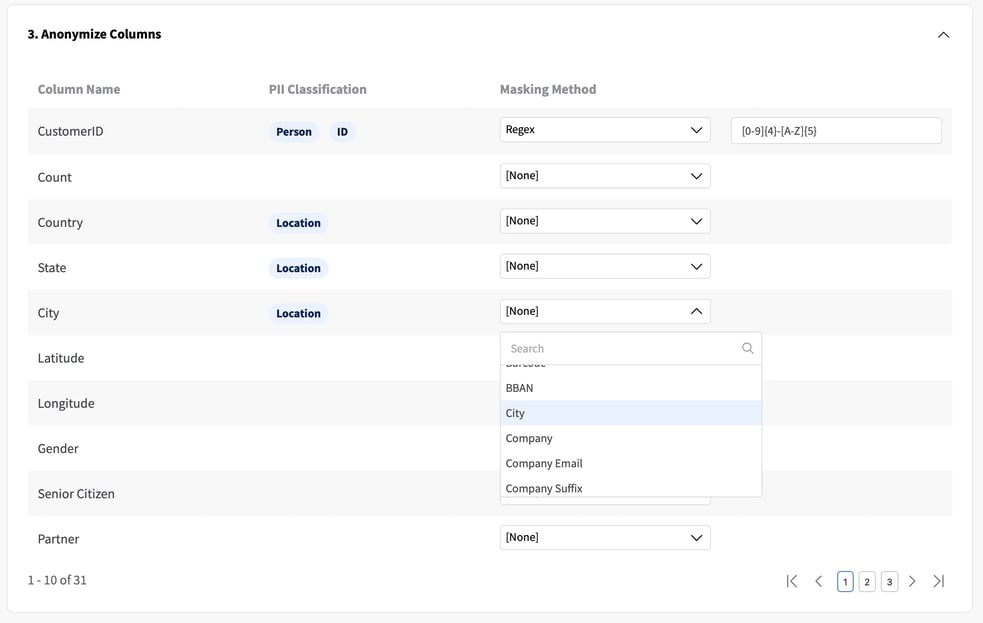
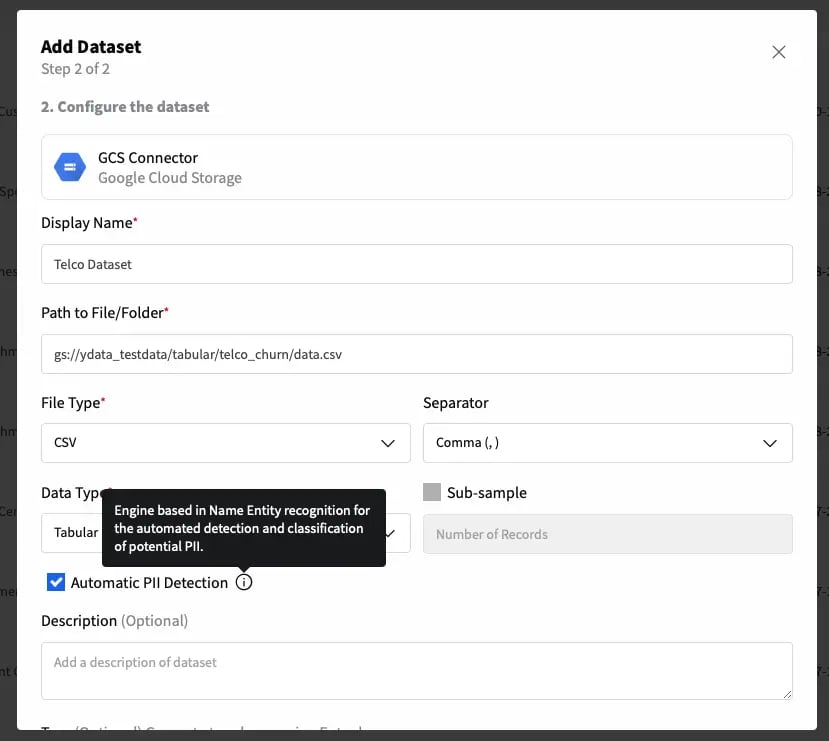
The process starts when adding your datasource. If “Automatic PII Detection” is enabled, Fabric automatically interprets the input data and identifies potential PII information:
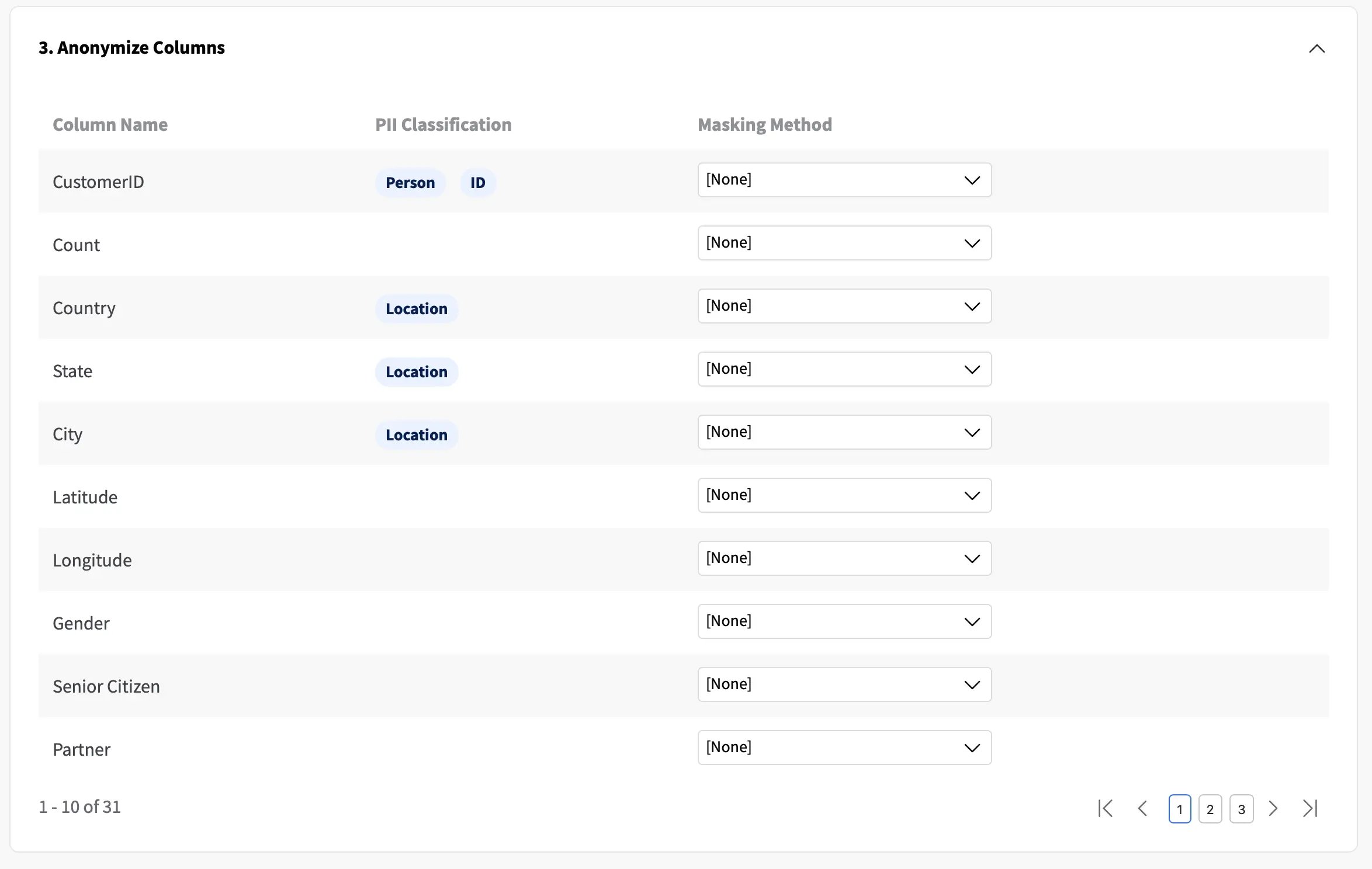
With PII Identification, dataset attributes that reflect potential private information will be highlighted during the synthesis process. As expected, ID columns consist of direct identifiers and therefore are tagged as potential privacy leakers that should be removed or anonymized during synthesization. Other columns such as City, Country, State, Zip Code, and others may consist of quasi-identifiers and users can assess the need to mask them as well, depending on the business requirements and downstream application of the synthetic data.
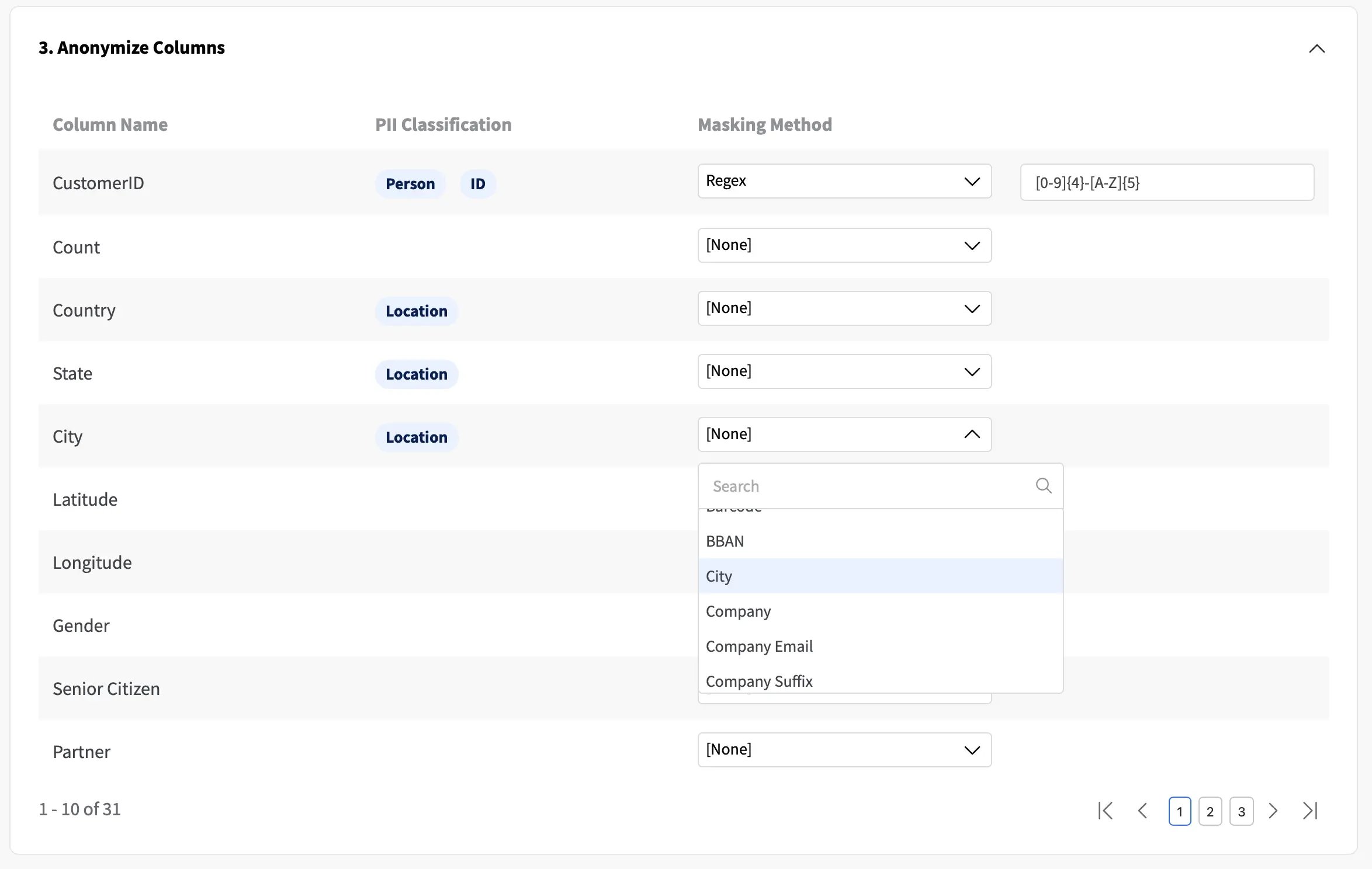
Fabric provides several predefined anonymization options that correspond to the most common scenarios (e.g., city, address, names, IP address) and also allows to specify a regular expression to match any specific formats that your data might require (e.g., an internal ID format). In this example, we will showcase how to anonymize the customer ID and the City columns:
- CustomerID follows a format with 4 numbers and 5 alphabetical characters, separated by an hífen, e.g., “3668-QPYBK”. For that reason, we will specify a REGEX masking for the anonymization;
- City, on the other hand, can leverage the default option to generate fake city names.
If the goal of the synthetic data is to be used both for data sharing and to allow data teams to extract actionable insights, we can define an optimized threshold between privacy and fidelity. This ensures that while sensitive information remains private, the newly artificial data holds real data value and mimics the original data behavior:
Conclusion
Combining anonymization and high-quality synthetic data is key to unlocking data sharing and development initiatives, guaranteeing that the generated data remains adjusted to the business needs while safeguarding potentially personally identifiable information.
Fabric enables a data-centric approach where ensuring privacy is one of the main goals right from the start. From potential PII detection to the incorporation of anonymization and differential privacy into the synthesis process, Fabric empowers users to generate high-quality and privacy-preserving synthetic data that allows organizations to break out of data silos and truly leverage the potential of their proprietary data. Moreover, you can also consider conditional sampling to further align the synthetic data with your business requirements.
Take charge of data privacy with Fabric by signing up for our community version! You can also contact us to learn more about the benefits of anonymization and privacy-by-design in your synthetic data generation. We’ll be happy to guide you through it.