In today's data-driven world, synthetic data has emerged as a valuable asset for organizations across various industries, from telecommunications, transportation, finance, e-commerce, and healthcare.
While leveraging realistic and high-quality synthetic data is crucial across all industry sectors, some domains are particularly affected by specific data quality issues – such as class imbalance and underrepresentation – that need to be taken into account when generating synthetic data.
A straightforward example is fraud detection, where data is heavily imbalanced: non-fraudulent events comprise the great majority of the datasets, whereas fraudulent events are rare, and therefore harder to map out. Another example could be insurance assessment, for instance. In such situations, generating synthetic data that aligns with specific conditions or patterns is essential.
To successfully address this need, YData Fabric introduces a new UI experience incorporating a Conditional Synthetic Data Generation, that allows to solve use cases such as fraud augmentation or bias mitigation in a simple guided flow. The new flow allows users to customize synthetic data generation in order to tailor to specific data characteristics, without a single line of code.
In this article, we will explore the benefits of conditional sampling for synthetic data generation and how Fabric can be leveraged to tackle complex data domains.
What is Conditional Synthetic Data Generation?
Conditional synthetic data generation is a process that empowers organizations to train and generate synthetic data by specifying certain conditions or input information. Conditional data generation (sometimes called seeding or prompting) is a technique where a generative model is asked to generate data according to some pre-specified conditioning, such as a topic, sentiment, or specific values in certain features of a tabular dataset.
Through a synthesizer that was trained conditionally users are able to adjust the distributions of the generated synthetic data. Selecting specific conditions allows the generation model to learn the required input in more detail, and generate new synthetic samples based on the conditions as well.
All in all, synthesizers that are conditioned on certain data properties offer fine-grain control over the characteristics and patterns exhibited by the generated data, making it a valuable tool in data generation and manipulation:
-
Addressing Class Imbalance: Industries grappling with class imbalance, such as fraud detection and anti-money laundering, can leverage conditional synthetic data generation to generate synthetic data that balances class distribution. This facilitates improved model training and enhances the accuracy of predictions;
-
Mitigating Bias and Underrepresentation: Conditional generation facilitates the augmentation of existing datasets by generating synthetic samples that capture specific characteristics of real data. This approach proves invaluable when dealing with data underrepresentation, by improving the recognition of smaller subgroups of data. This not only enhances model training and performance but it additionally reduces the risk of bias and unfair predictions for subgroups.
The new Fabric experience for Conditional Synthetic Data Generation
To showcase the benefits of conditional generation we will use the Adult Census Income Dataset (License: CC0 Public Domain) in this blogpost.
This dataset is a collection of census data from 1994 mainly used for prediction tasks where the goal is to identify if a person makes over 50K a year. Each person is described by 14 features focused on personal information, which includes sensitive attributes such as race and sex.
This type of sensitive data is often associated with underrepresentation and bias, where the concepts underlying the minority subgroups of the population are not well learned by machine learning models, and therefore receive underperforming, and often unfair, predictions.
Through a quick look at the Data Catalog, we can see that our dataset has several issues, among which category imbalance stands as one of the most frequently found. For example, “Sex” and “Race” present a considerable level of category imbalance, which is crucial to handle to guarantee that ML models trained with this dataset will not be biased towards the most represented concepts (“Male” and “White” in this scenario).
To overcome this issue, we will leverage the creation of a conditioned synthetic data generator to augment our dataset in accordance to our needs, i.e., balanced distributions for both Sex and Race features.
We start by creating a new Synthesizer, where the Conditional Sampling must be enabled for the features that we wish to use for the conditional data generation.
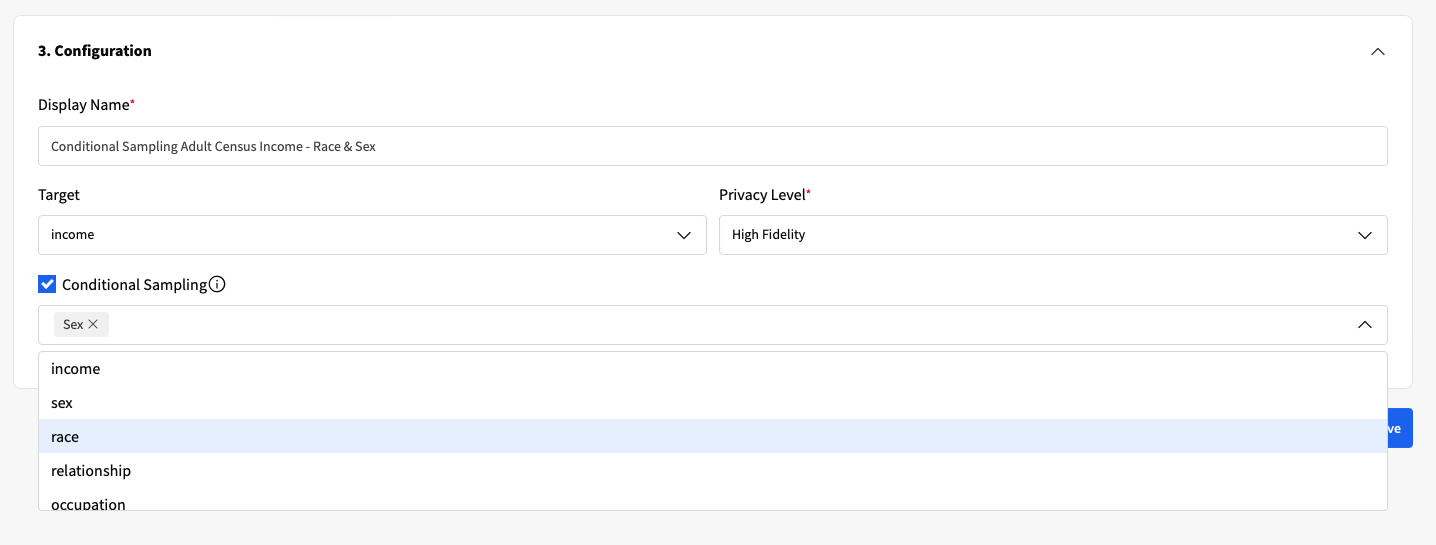
The synthetic data generation process can be conditioned to any number of columns, as long as they are categorical. For instance, you could further condition the data generation on workclass and education, to guarantee that the several demographic concepts in your data are equally represented in the synthetic data.
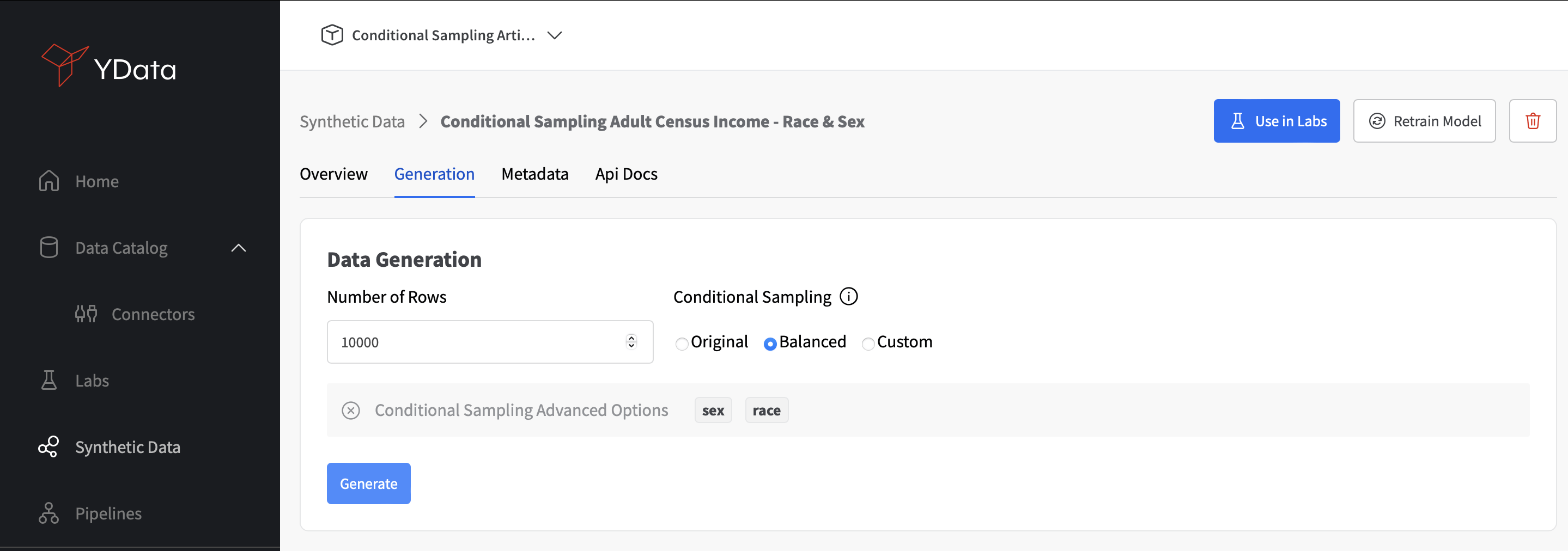
Once the Synthesizer is trained, we can now use the conditions introduced to the model when generating new synthetic samples. The model will generate new samples according to the specific conditions defined for Sex and Race.
Fabric allows the users to have a fine-grained control through the UI experience for the conditional synthetic data generation. In this case, we have selected a balanced setting for Sex and Race, meaning an equal distribution for the available categories. However, we could have decided to generate new data following the same distributions as observed in the original dataset, or even customized proportions for each of the conditioned feature values.
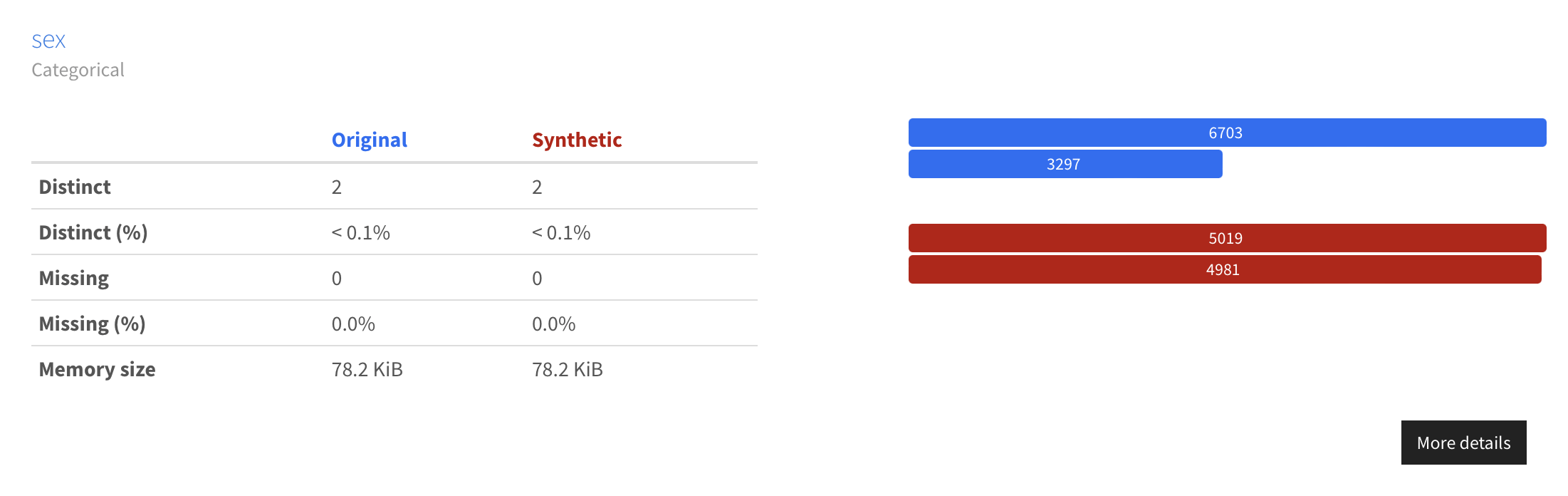
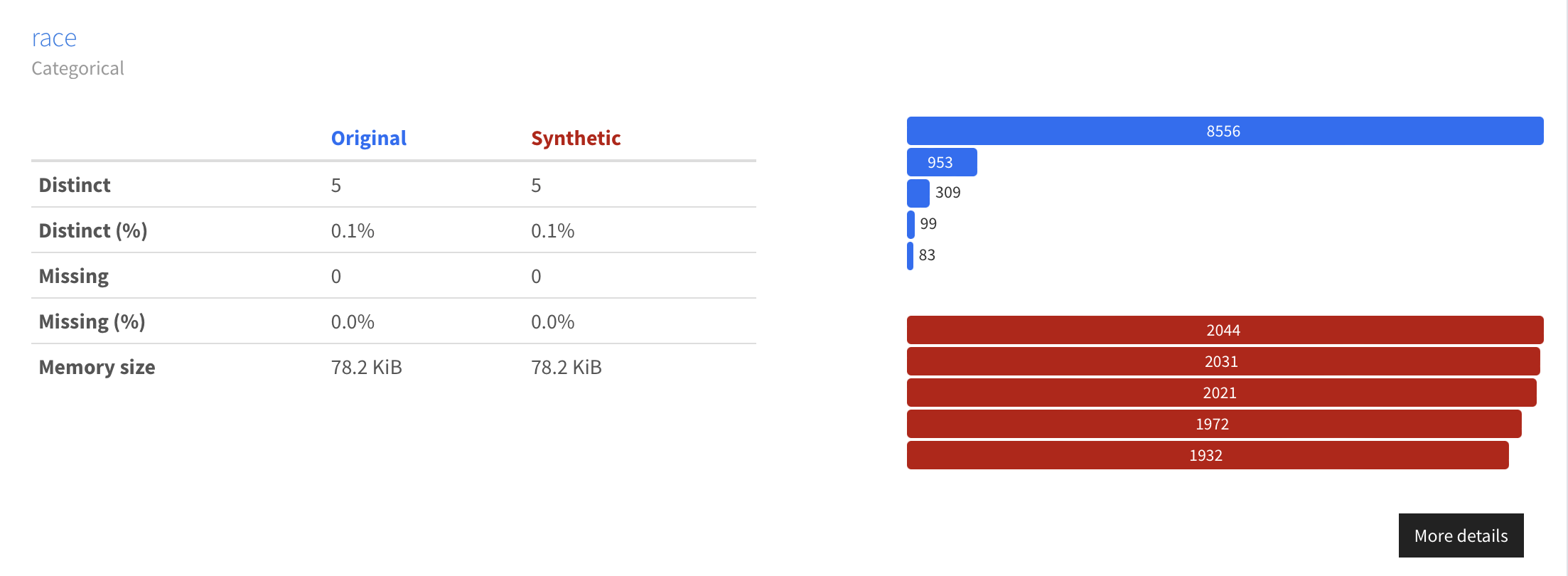
The newly generated data keeps all the existing relationships in the original data (as expected), while balancing the representation of the underrepresented subgroups.
Fabric SDK expands the flexibility, integration and customizability of the synthetic data generation flows. It offers user-friendly interactions for developers and a more granular control as well as integration possibilities with other platforms and systems. Check this example for the Conditional Synthetic Data Generation to learn more.
Benefits of Conditional Synthetic Data Generation for Organizations
Conditional sampling offers a multitude of benefits to organizations empowering them to unlock the full potential of their data assets:
- Cost/Time Efficiency, and increase in ROI: Synthetic data generation through conditional sampling reduces the need for extensive data collection or labeling efforts. This saves valuable time and resources, enabling organizations to accelerate their data-driven initiatives;
- Improved Model Generalization: Generating synthetic data that represents a diverse range of scenarios and conditions aids in building more accurate and robust models that generalize better;
- Ethical and Responsible AI Development: Conditional sampling empowers organizations to control the output and characteristics of synthetic data, ensuring ethical considerations and avoiding biased or discriminatory outcomes.
Conclusion
Leveraging conditional synthetic data generation offers organizations a game-changing advantage. By generating high-quality synthetic data that aligns with specific conditions and requirements, organizations position themselves at the forefront of optimal data-driven decisions, driving growth and competitiveness in a Data-Centric AI paradigm.
Try synthetic data generation and the benefits of a conditioned generation for your business with Fabric Community. Check out our Github for more advanced use cases or experiment with our SDK experience for synthetic data generation.
Cover Photo by Scott Graham on Unsplash



