One of the most valuable and unique characteristics of synthetic data is that it keeps the properties and behavior of original data without a one-to-one link with the real events, thus fostering data privacy and enabling secure data sharing.
In this article, we’ll explore what are the most robust metrics to ensure that your synthetic data is privacy-compliant while keeping the original data granularity and diversity.
Does my synthetic data contain a copied record from the real data?
To safeguard individual privacy through synthetic data, it is crucial to preserve the fundamental characteristics of the original data while mitigating the risk of re-identification. This risk varies, ranging from scenarios where records are copied from real into synthetic datasets to instances where one can infer real data information by identifying a closely resembling synthetic record.
In Fabric’s automated system to ensure synthetic data quality PDF report, several metrics are offered to assess the privacy properties of the generated data.
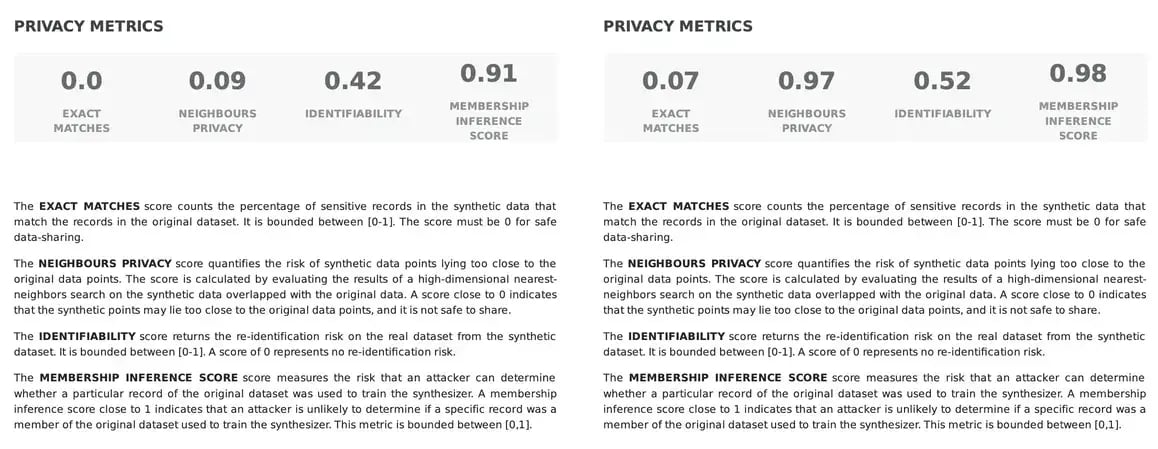
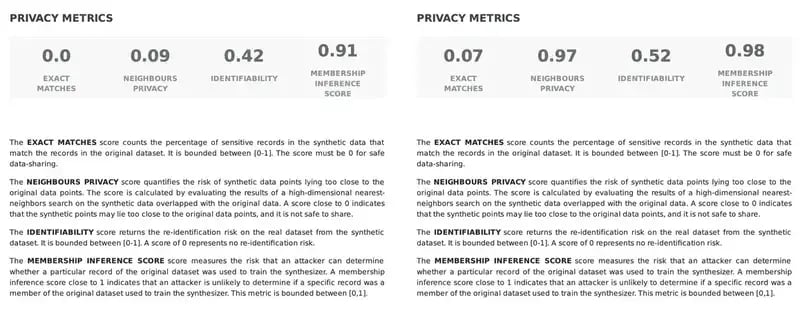
The Exact Matches Score measures the percentage of records in the synthetic data that precisely match those in the original dataset, ranging between [0,1]. For safe data sharing, this metric should be closer to 0: a high score may indicate a potential risk to privacy, as it suggests a direct correspondence between synthetic and real data points. However, a percentage greater than 0% does not necessarily indicate a privacy breach; rather, it signals the need for assessment of duplicated records. For instance, if identical records are duplicated in the original dataset, it is expected that a similar occurrence will occur in the synthetic dataset. For that reason, it is important to validate the quality of your original data before moving forward with the synthesization process.
How close are my synthetic data points to the real data points?
While the Exact Matches Score focuses on direct matches, the Neighbours Privacy Score Fabric’s Synthetic data quality PDF report evaluates the risk of synthetic data points being in close proximity to the original data points. Similarly, this score ranges from [0, 1] and scores closer to 0 signal a potential privacy risk, indicating that synthetic points may be situated too closely to the original data points, compromising confidentiality.
In the following example, while both synthetic datasets have 0% exact matches, the synthetic data on the right has a much higher score of neighbors’ privacy. This indicates that while there is no one-to-one matching in both cases, on the left side, the real data points lie too close to the synthetic ones, possibly posing a privacy risk, whereas, on the right side, the real data points are not easily identifiable by adjacent points in the synthetic data.
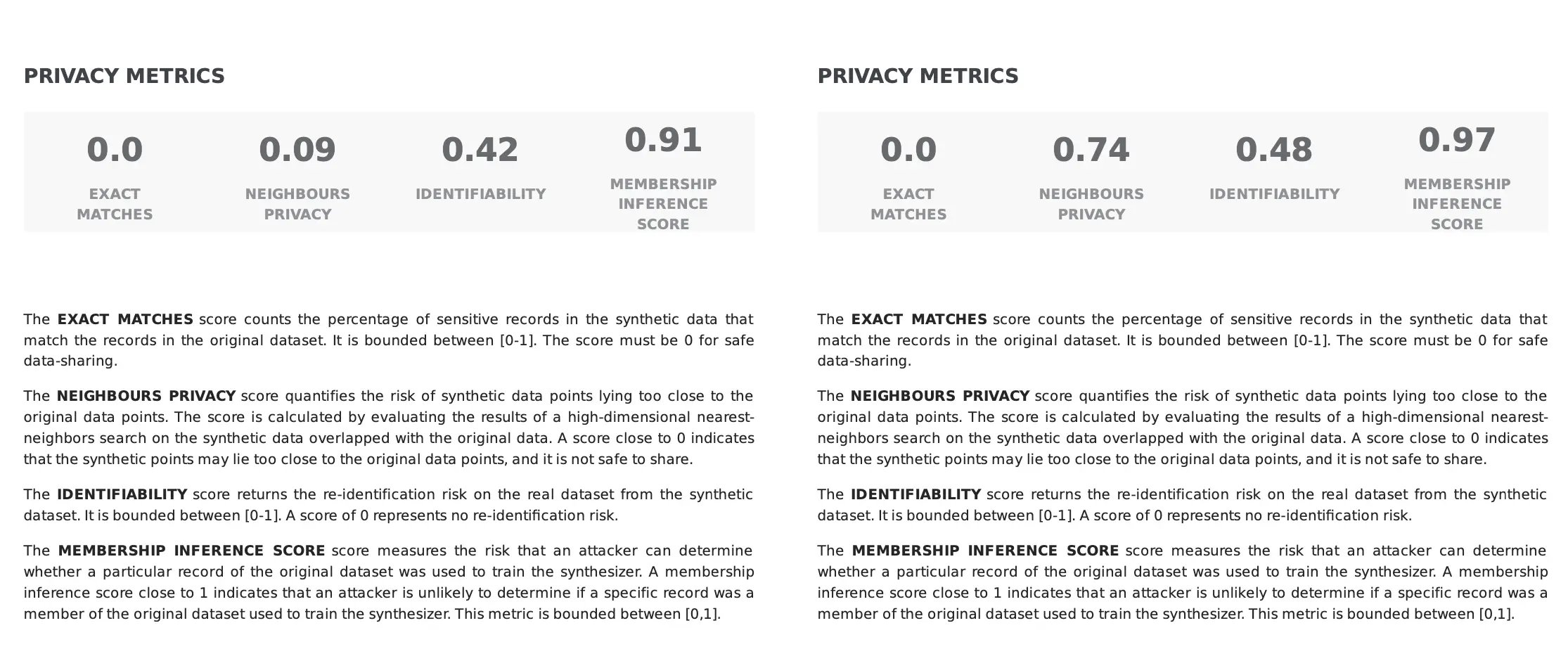
As shown in the examples shown above, there are additional components to consider when evaluating synthetic data privacy: Fabric Synthetic Data incorporates several privacy controls that offer a trade-off between fidelity and privacy, ensuring a robust data generation.
Conclusion
Promoting privacy compliance in your artificial data is crucial to fostering trust and confidence in synthetic data. By prioritizing data privacy, you’ll not only be able to mitigate potential disclosure risks but also safely break your data silos and fully leverage synthetic data in your AI projects and initiatives!
Dive into Fabric Community to start leveraging synthetic data in your organization and keep an eye on our following article, where we’ll explore the remaining privacy scores (Identifiability and Membership Inference Score), their role in assessing the re-identification risks, and how Fabric globally assesses synthetic data privacy.
If you run into any questions, feel free to contact our team. You’re also welcome into the Data-Centric AI Community to connect with other synthetic data enthusiasts.