According to Alation’s State of Data Culture Report, 87% of employees attribute poor data quality to why most organizations fail to adopt AI meaningfully. Based on a 2020 study by McKinsey, high-quality data is crucial for digital transformations to propel an organization, past competitors.
As machine learning algorithms coding frameworks evolve rapidly, it’s safe to say the scarcest resource in AI is high-quality data at scale. High-quality data is the bottleneck.
Despite several findings on the importance of data in the AI industry, more than 90% of research papers in the AI domain are still model-centric. According to Andrew Ng, this is due to the difficulty in creating large datasets that can become generally recognized standards.
Thus the data-centric movement was born. The movement represents the recent transition from focusing on modeling to the underlying data used to train and evaluate models.
As a next step in the movement, today we’re excited to announce the Data-Centric AI Community — a place to discuss data quality for data science.
Data-Centric AI is the approach to AI development that considers the training dataset as the centerpiece of the solution instead of the model.
Let’s take a step back and understand the hype on data-centric AI. Coined by Andrew Ng, data-centric AI emphasized the importance of focusing on data quality over algorithms and models. Further, deeplearning.ai and Landing AI announced the first-ever data-centric competition. Not only did it create awareness but also inverted the traditional competitions and asked to improve a dataset given a fixed model.
Finally, in 2021, the Data-Centric AI workshop was conducted to cultivate the DCAI community into a vibrant interdisciplinary field that tackles practical data problems. Several companies have adopted the approach and produced results. According to Landing AI, Some improvements from the adoption of a data-centric approach include:
build computer vision applications 10x faster
reduced time to deploy an application by 65%
improved yield and accuracy by up to 40%
With all the proven benefits in the industry, launching the DCAI community aims to complete the missing piece in the data-centric AI movement.
The 3 Pillars of the Data-Centric AI Community
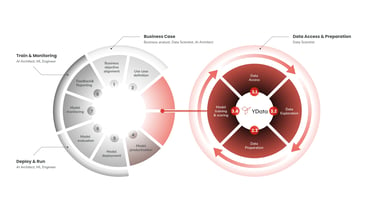
While the data-centric approach is still evolving and can span over various stages of a machine learning lifecycle, we’ve identified the most significant pain points amidst the data scientists and aim to focus on those in the DCAI Community.
We call them the 3 pillars of the DCAI community:
Data Profiling: Understanding the existing data is the first step to improving the data. Profile your data in a few lines of code. Give it a try on pandas-profiling!
Synthetic Data: It is artificially created that keeps the original data properties, ensuring its business value while being privacy compliant. Give a try on ydata-synthetic!
Data Labelling: Isn’t it one of your most significant pain points in data quality? The DCAI Community cultivates meaningful discussions around this and other topics in our slack workspace!
At the Data-Centric AI Community, we believe that together, we can actively change the paradigm towards better data. We want to bring together experts from the industry and foster meaningful conversations.
Expect a regular calendar of events and content creation that will help you understand this approach better and allow you to become a data-centric ai evangelist. As we partner with experts in the industry, you will get the much-needed guidance directly from those who have already done what you plan to do.
Accelerating AI with improved data is at the core of what we do, and this open-source community is yet another step towards our meaningful journey. We invite you to be part of it — together, the possibilities are endless.
Fabiana Clemente is CDO at YData. Accelerating AI with improved data. YData provides the first data development platform for Data Science teams. 195