Why adopting the Data-Centric paradigm of AI development?
Data-centric AI and the reshape of the tooling space
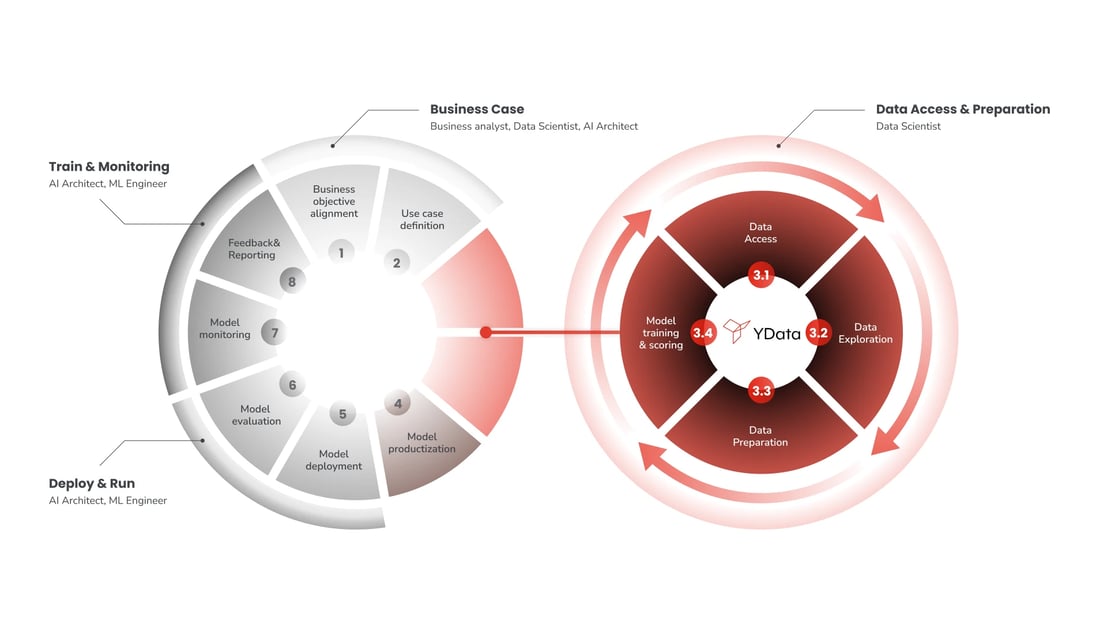
The end-to-end development of Data Science solutions can be broadly described as the process of analysis, planning, development and operationalization of a business problem that can be solved through an automated analysis of input data This process starts with the business pain and goals and goes through multiple stages. This lifecycle can be summarized as follows:
As Data Science practitioners we are already aware that the expected output of this cycle is solution composed by:
AI System = Code + Data, where code means model/algorithm
which means that in order to improve a solution we can either improve our code or, improve our data or, of course, do both.What is the right balance to achieve success?
With the datasets publicly available, through open databases or Kaggle, for example, it is understandable why a more model-centric approach have been followed: data in its essence more or less well-behaved, which means that to improve the solutions, the focus had to be on the only element that had more freedom to be tweaked and changed, the code, more specifically the models. But, the reality that we see in the industry is completely different. This was the perspective shared by Andrew NG in 2021, and its adoption has been growing ever since.
In the next sections, we will explore further this novel concept and present some solutions for real world problems. YData is a pioneer in helping data scientists build high-quality training datasets, offering several open-source tools and an enterprise platform built by data scientists to empower data scientists with the right tools and flows to adopt a Data-Centric AI approach.
Data-centric AI: the paradigm and tooling space
As the old saying “Garbage in, Garbage out” assumes a new meaning under the new paradigm of Data-Centric AI, the changes deeply affected the process of developing Data Science solutions and the infrastructure and products to make it possible. The typical development flow and tooling to support it did not evolved much, as referred to by the Anaconda’s 2021 report: there’s a huge need for enterprise tooling to correctly support data teams in preparing the data — mostly because the majority of the tools are open-source, not scalable and ad-hoc per project.
As Data-Centric AI embodies the point of view on how data should be analyzed and prepared, more tooling in the area of data programming and pipelines have been evolving and becoming available. The question is no longer about“How to build the best model?”but rather“How to better feed my model?”. Within the new paradigm, the process of analyzing and preparing the data is more and more an “end-to-end” exercise of the Data Science development —how does the data look like now and after improvements,how does a certain improvement impacts the performance of my data,how can I evaluate the quality of my data through the process, and the list goes on. Data profiling, augmentation, cleaning and selection, and robustness, are now considered core elements of the Data Science toolkit that need to be combined, tested and iterated as much as we would iterate a model during the process of hyperparameter tuning.
Having in mind this paradigm shift and the needs of data scientists, a new way of developing solutions was needed to materialize the Data-Centric AI promise.
YData — Why, What and How?
YData is a pioneer in helping data scientists build high-quality training datasets for Data Science solutions and the creator of DataPrepOps — Data Preparation Operationalization — which in a nutshell, advocates for constant iteration on the training dataset, guided by a systematic approach of versioning and transformations automation based on empirical results.
YData adopted the term Data-Centric AI as its meaning is conceptually the same and became the company behind the community efforts for this movement.
YData’s flagship product is a data-centric platform that accelerates the development and increases the RoI of AI solutions by improving the quality of the training datasets.
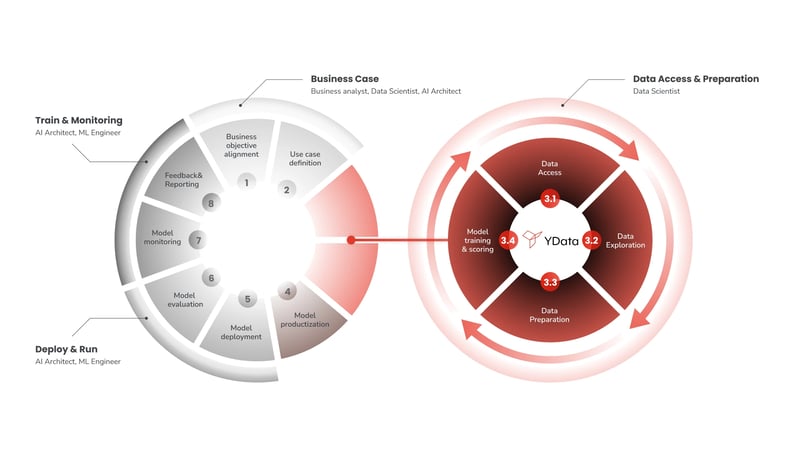
Data scientists can make use of automated quality profiling, access and improve datasets by leveraging, between other techniques, state-of-the-art smart synthetic data generation. Figure 2 illustrates how the data-cycle and the model-cycle integrate into one another and how it completes the Data Science lifecycle.
How does it work?
1 — The data quality profiling feature helps them better understand the existing data and what needs to be fixed;
2 — Embedded IDEs (Jupyter, VS Code, etc) and connectors (RDBMS, DWs, cloud object stores, etc) make it easy and familiar for data scientists to make decisions upon the data preparation;
3 — Smart synthetic data generation that can be used for privacy use cases, bias mitigation and imbalanced datasets. In the end, making it possible to generate more accurate scenarios for better simulation and analysis;
4 — Scalable pipelines allow users to constantly experiment with data preparation at scale until good results are achieved
Get well acquainted with your data
Whenever a certain business requirement is brought to the data teams, the first question to be answered is probably related to the feasibility of answering this problem through analytics and/or Data Science.
Let’s consider the following: as a Data Scientist, the first set of questions are the following:
“Do I have data to answer the business questions?”
“Is the data accessible? Where?”
As soon as the Data Science team accesses the data, other challenges and questions arise, this time already about the intricacies of the data itself:
“Do I have missing data?”
“How does my missing data behave?”
“Do I have labels? Are they trustful? How was the labeling process done?”
“Is my data too noisy?”
All these questions need to be answered with univariate and multivariate analysis that are time-consuming and many times ad-hoc per project. The complexity of doing so increases exponentially with the number of columns and rows of the dataset.
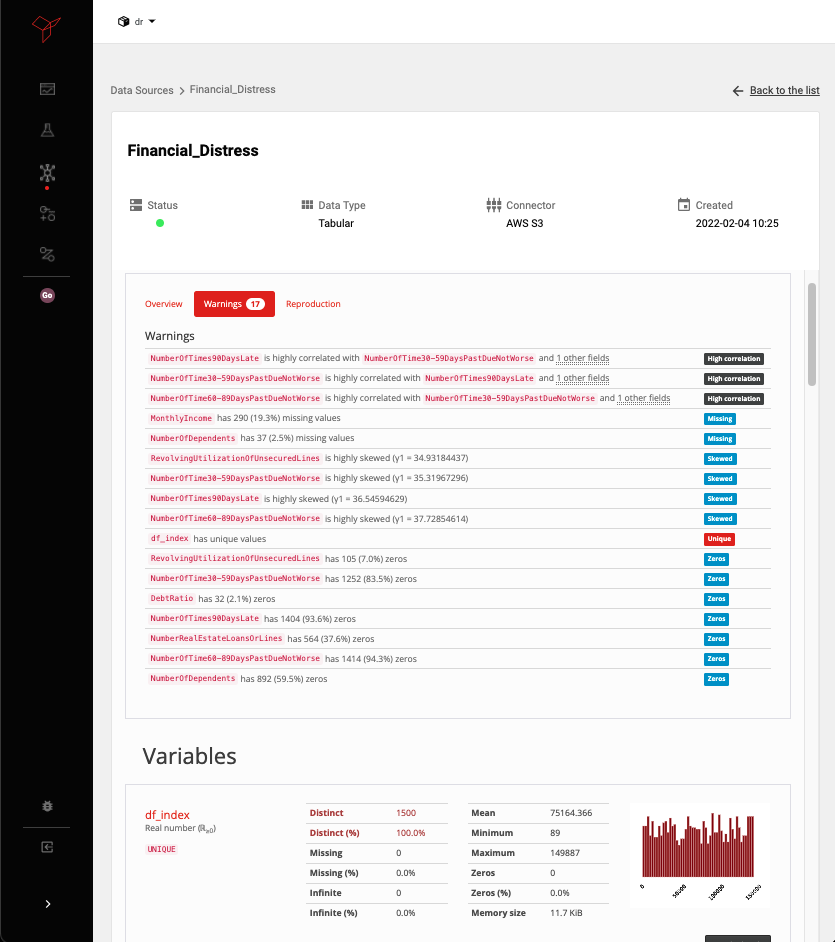
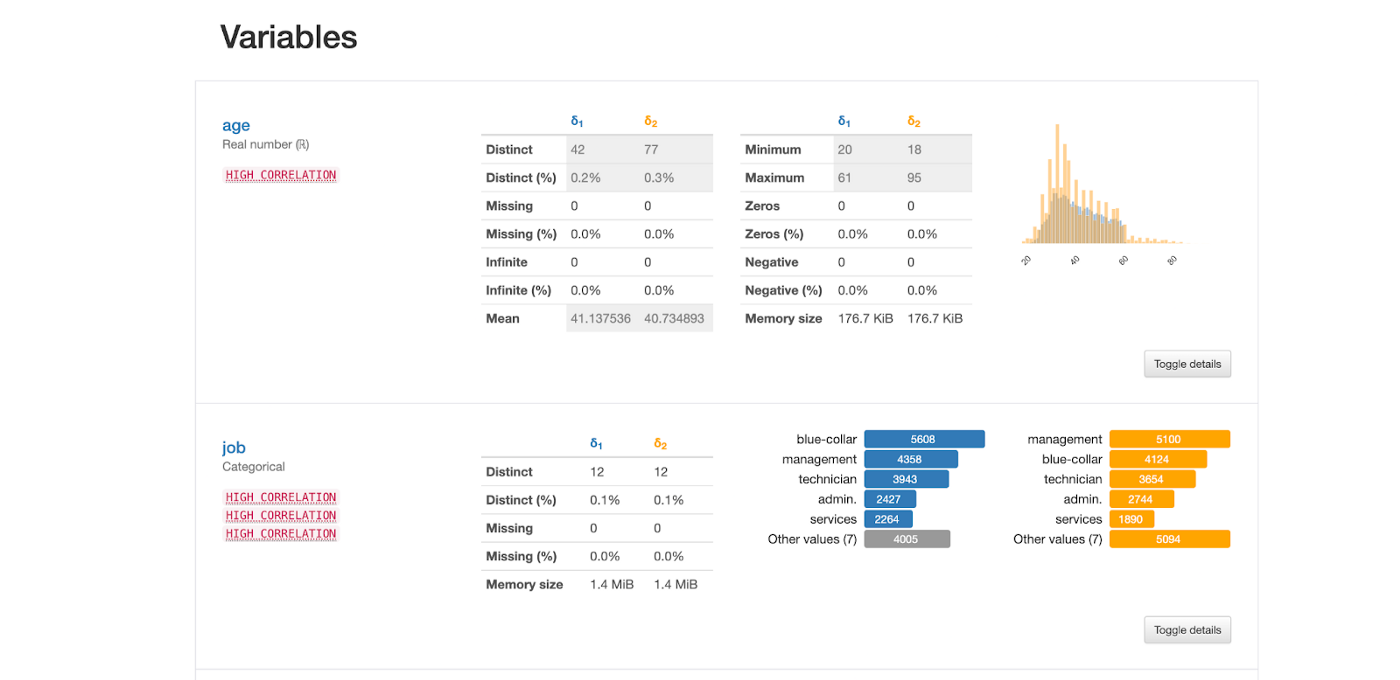
YData offers a standardized and visual understanding of the data, as well as built-in functionality to flag potential challenges such as high ratios of missing data, infinite values, inconsistencies, skewness, high correlation, high cardinality, non-stationarity, etc. The data profiling not only helps in the feasibility study for the development of Data Science projects, but also to align the business with the technical teams.
After all, at the beginning, both parties have expectations — on the business side it might be to achieve 90% of accuracy in identifying a certain behavior, while on the technical side it might be reach the objectives and deliver within the time-to-market expectations.
But when Data Scientists spend 80% of their time cleaning and preparing data, how can they plan for what comes next and test several hypotheses? And if dirty data is the challenge, how can we understand it faster and put everyone on the same page? Data profiling plays a big role in providing a quick but deep understanding of the existing data and saving time and money in the data preparation process and iterations with the business teams. It not only provides information about the features of the dataset but also warns about what can be an error in the data itself. Figure 3 illustrates both scenarios.
Synthetic data generation
Synthetic data is artificially generated data that doesn’t match any individual record. While resembling real data, synthetic data ensures both business value while being compliant with privacy regulations. Synthetic data is a perfect solution for safely sharing privacy data thus fostering innovation and collaboration as it reduces the risk of profile re-identification, but not only. In fact, it can be a powerful tool in cases where collection of data is expensive and time-consuming (eg. rare events and anomalies, such in fraud detection or insurance claims use cases), but also in cases where there are clear class imbalancement (eg. Bias and Fairness challenges, like we find in Credit Risk scoring use cases).
Generating synthetic data that is able to reflect the core statistical properties of real and underlying real-world behavior is much cheaper compared to collecting or labeling large datasets while supporting Data Science projects development without compromising privacy.Synthetic data is the future of data science development, according to several sources. Synthetic data has the potential to be pivotal for data scientists, enabling them with the tools and data they need.
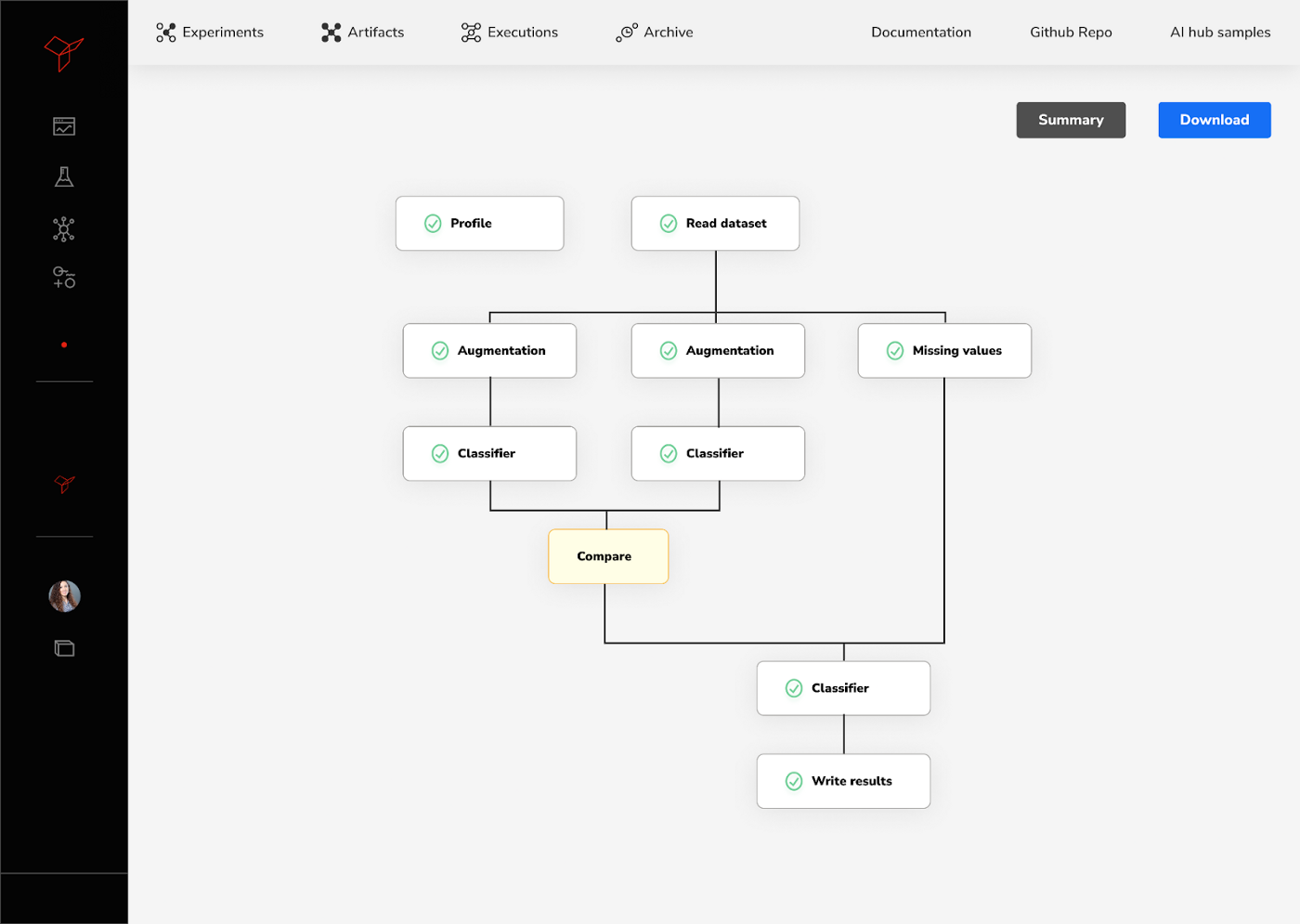
YData supports structured data synthesis, both tabular and time-series (eg. Transactional data). Within the platform, the process of synthetic data generation is enabled through the UI, API but also, programmatically, for a more controlled, customized and flexible synthesis process. It can be used to synthesize data for many data science applications, such as augmentation, balancing or imputation of missing values, but also for sharing purposes within the organization. Figure 4 depicts the synthetic data generation flow, which can be one of the building blocks of a complete data science solution.
Data preparation pipeline
Hyperparameter tuning is the process of parameter optimization, oftenly linked to one of the steps to build the optimal Machine Learning model performance. The main question to be answered by this process can be summarized as “What are the best model parameters that optimize the performance of my model?”. In reality, the same question applies to the process of building the right data preparation pipeline — “What data preparation steps should be included to improve the performance of my model?”.
YData’s Pipelines allow data science teams to easily build scalable pipelines as building blocks while exploring and comparing the effect of different data preparation decisions. The building blocks can be defined both programmatically or by assembling different Jupyter Notebooks or Python scripts.
Besides the flexible Pipeline engine you can also find built-in functions for missing values imputation for tabular and time-series with high rates of missingness, synthetic data generation for augmentation of rare events or whole dataset augmentation, plus many more recipes for common data quality use cases.
Data debugging — understand the unknown
After a model reaches production, or even while validating the initial model development against the validation set, the performance of the model may deteriorate. The root cause of this problem may not be the model itself but adata quality issue: some entries may have been mislabeled or some records may contain corrupted or incorrect information. How can the Data Scientist identify these records?
YData’s Pipelines is a powerful resource to understand the impact of individual records in the model performance by benchmarking the model against training and validation sets. Our built-in scoring system, which includes but is not limited to Q-Score(measures the positive relational algebra of a query) is a powerful step to better understand what went wrong.
Finally, what is better than a visual comparison between two sets of data to better spot the problem origin? It is possible to easily compare the distribution and behaviors of two separate datasets of data through a comprehensive visual experience.
What’s next?
Data-Centric AI is clearly a big breakthrough for the development of AI solutions. This concept empowers data scientists to take the most out of the organization’s data assets, and enables them to do more and better in an enjoyable way. It is expected to see more Data-Centric AI tooling to emerge over the next years, each one with a different focus area, from data profiling, labeling, monitoring, synthetic data, data versioning and lineage, all towards concept drift and causality analysis.
Fabiana Clemente is CDO at YData. Accelerating AI with improved data. YData provides the first data development platform for Data Science teams.