ydata-synthetic v1.0 introduces a state-of-the-art generative model that generalizes for a bunch of datasets in a user-friendly interface.
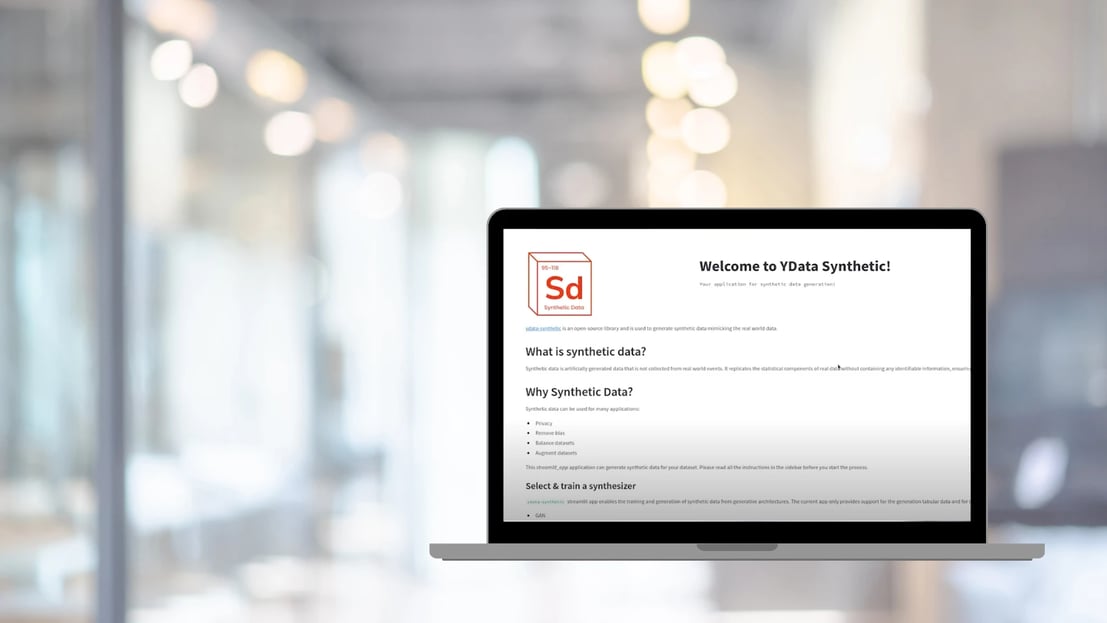
We are thrilled to announce that ydata-synthetic v1.0 is officially out! With an improved generative model and a Streamlit interface, the new release will guide you through an efficient and effortless flow with no code, from reading your datasets to profiling your synthetic data.
In software development, v1.0 means full functionality and stability, and that is what the new ydata-synthetic release delivers! Better stability for tabular synthetic data generation and a UI interface that delivers a guided step-by-step for synthetic data generation: from training all the way to sampling and profiling.
And rest assured, more recent python versions (3.9 and 3.10) are now supported by one of the most popular package for structured synthetic data generation.
But let’s dig a bit deeper into some of the most exciting bits of the release!
New Generative Model served with a New UI Experience
In this new release, we introduce two new key features that will make synthetic data generation easier, more fun, and more friendly if you are new to the synthetic data concept.
The latest version of the package brings an exciting guided UI experience for the generation of synthetic data. The flow guides you through the whole synthesis process without the need for a single line of code - the ydata-synthetic Streamlit app does that for you. From reading the data and training a synthetic data generation model to sampling and visualizing synthetic data with one of your most loved EDA packages (ydata-profiling), we ensure that your experience is seamless and exciting!
%20-%20Blog.gif%3Fwidth=768&height=432&name=ydata-synthetic%20V1.0%20(GIF)%20-%20Blog.gif "ydata-synthetic V1.0 (GIF) - Blog")
And because simplifying the synthetic data generation experience was one of the most requested features from the community, we have also incorporated a new generative architecture (CTGAN) that will deliver reliable results even if you have a lot of categorical data, without the need to develop your own data preprocessing flow.
We are happy to keep contributing to the community with resources and clarity of the benefits, challenges, and know-how to best fine-tune generative models for structure data!
You are challenged to step into a never seen open-source experience for synthetic data generation, where you can not only learn about generative model architectures but also compare and visualize the achieved outputs. Also, if the ease of use and the UI experience have caught your eye, then you must definitely give YData Fabric a try!
Thank you for your continued support, and we look forward to your feedback. You may find us on Discord to get help with troubleshooting or request new features!