Teams innovating around data quality, availability and security are pushing the boundaries of what is still a young ‘Privacy-Enhancing Tech’ (PET) landscape. Click here to learn why we are excited about what the future of synthetic data, federated learning and other PETs hold.
The Data Explosion
Enterprises fail to innovate because of their inability to access their own data
Data has become the lifeblood of our digital economies. The companies that deliver the products and services that we consume on the web leverage information - on our profiles, our tastes, behaviours, and more - to provide tailored and targeted solutions for us as well as to serve their own analytics needs. As AI & ML continue to penetrate all walks of life, the data fed into models as a representation of what will become the model's knowledge, becomes all the more important.
We are officially in the zettabyte era of data, with amounts of information being created and captured online to continue to compound at vast rates. However, along with this explosion of digital information, a number of challenges have arisen.
With more noise than signal, wading through the oceans of data relevant for your decision-making processes is becoming increasingly difficult, placing greater emphasis on data curation and metadata management.
As a result, many enterprises can’t innovate rapidly due to their inability to access their own data. Data scientists are waiting weeks and, in some cases, months to get their hands on the information that is central to uncovering insights and training models to power the next generation of intelligent solutions. This poor data access and quality plague businesses across all sectors.
There needs to be a revolution in data access, quality management, and collaboration, albeit in a way that successfully navigates data privacy laws and governance standards. In response, over the past few years, there has been a plethora of companies building novel approaches to solving these issues.

What are we excited by?
1. Synthetic data tools deeply integrated into data scientist workflows and embedded within applications.
Synthetic data companies are allowing users to produce computer-generated data that mimics the properties of real datasets without exposing underlying personal information. In cases where data is sensitive, inaccessible due to restraints on data usage, or incomplete, this becomes incredibly useful. For example, when faced with scarce training data to develop natural-language-understanding systems for new languages like Hindi and Brazilian Portuguese, the Alexa AI team at Amazon used synthetic data to learn general syntactic and semantic patterns, taking these patterns to generate thousands of similar sentences for training.
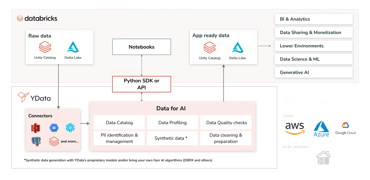
Balancing datasets becomes one of the important components of ensuring high data quality, which startup YData places great emphasis on. Through their data development platform, they provide automated data quality profiling, to enable data scientists and engineers to curate their existing datasets and understand biases and gaps. This is then coupled with synthesizers that can serve multiple purposes, from generating additional for dataset balancing to de-identification for collaboration and compliance purposes.
A number of operators we’ve spoken to find this capability useful when it comes to creating more edge cases to complement model training, as well as using it in validation to test models.
The deep learning techniques behind Synthetic Data, namely VAEs and GANs, open up interesting possibilities for the future of media creation. Whilst MMC Portfolio company Synthesia uses GANs to generate AI avatars from text, we’ve seen others use the technology for privacy purposes related to unstructured data. For example, Brighter-AI’s deep natural anonymisation protects the identities of faces picked up from cameras collecting video for autonomous vehicle model development, whilst trying to maintain facial expressions and gaze to provide signals of intention. Whereas Syntonym obfuscates identities in real-time, enabling developers to build this into their apps for use cases like the protection of video therapy patients.
2. Collaboration unlocked for ML using federated learning architectures
What if, instead of taking data to the model, we were able to bring the model to the data?
Federated Learning, a machine learning technique based on decentralised computing, offers this promise. To achieve this, an ecosystem of data holders are sent an algorithm or statistical model to be trained, doing so locally and sharing results with a central server to be aggregated into a global model. This becomes useful in cases where an ecosystem of collaborators have proprietary/sensitive data and are sceptical about sharing it.
For example, during the Covid-19 pandemic, 20 healthcare institutes collaborated on a study to predict future oxygen requirements of infected patients using inputs of vital signs, laboratory data, and chest x-rays. The training of their Clinical Decision Support (CDS) algorithm took place on a federated learning architecture, with the CDS then being used to predict a risk score to support decisions to admit infected patients to the hospital and to help determine the level of hospital care they will likely require (flores et. al).
Companies building solution to make such technology more commercially available include Apheris, who are building a Federated MLOps platform to enable data scientists and enterprises that use the platform to run analytics on decentralised sets of information in a secure manner, building collaborative data ecosystems, such as the study above. These applications span beyond healthcare, to areas like financial services, manufacturing, and more.
3. Tools that enable computations on encrypted data
But perhaps the holy grail of data security, information collected on users would remain fully encrypted in transit, at rest, and in use. Research and development in homomorphic encryption has persisted for 50 years to achieve a standard that allows mathematical transformations to the underlying data whilst it remains encrypted.
There remain significant challenges to operationalising HE, particularly when it comes to the computational load and speed of processing, as well as the complexity of operations that can be run—limiting HE applications to small sets of data and simple transformations of data. However, a number of teams continue to push the envelope in research and commercialisation of the technology.
Ravel Technologies for example, which came out of stealth in August 2022, has brought together a team of academics and researchers to push the boundaries of HE. Ravel claims to have made a big breakthrough over the past 4 years, having developed their own approach that allows them to implement fully homomorphic encryption (FHE) at scale, across a dataset of any size. Applications they’re working on include SQL databases that enable encrypted queries over ciphertext, and integrating into financial exchanges to protect plaintext trade information.
What's next?
There are more companies building privacy-enhancing applications across Differential Privacy, Multi-Party Computation, Data Vaults, and more. But we’re in the early innings of these technologies reaching mass adoption. There still remains a great amount of research and product development left to reach this point, particularly with more technically challenging techniques like homomorphic encryption.
Whilst PETs have the potential to unlock innovation by mitigating risks around data privacy, unlocking data access and contributing to improving overall data quality. many of these technologies can’t be considered silver bullets to achieve these goals. They must be met with strong governance to be truly taken advantage of. Leading applications will also combine multiple PETs with targeted use cases, and deeply integrate into existing data workflows. We’re already seeing that with some of the companies mapped above, and the lines that separate them will continue to blur.