The Power of Data Quality, Orchestration, Profiling, and Synthetic Data
Retail is not only a fast-paced but also a highly competitive landscape, demanding from the players to be always ahead of the competition. The adoption of AI and data-driven strategies have shown to be crucial for retailers and e-commerce businesses to not only survive but thrive. This article explores the pivotal role of data quality profiling, synthetic data and data pipeline in for the adoption of successful AI strategies.
Data Quality foundational for Retail Success
Data quality is the bedrock upon which successful retail operations are built. Inaccurate or inconsistent data can lead to costly errors, affecting customer satisfaction and operational efficiency. In the retail sector, where precision is key, ensuring high data quality is non-negotiable - the same should be true when starting the journey into the world of data-driven solutions!
But, the good news is that tracking and ensuring the quality of data in Retail, does not need to be an issue. In fact, there are several tools that one can adopt in order to improve the process to acquire and process data, like robust data profiling, validations and even the adoption of synthetic data. Furthermore, with the implementation of automated processes that identify and rectify anomalies, businesses can not only identify but also maintain accurate and reliable data, leading to improved decision-making and operational excellence.
Data Profiling and Validations: Ensuring Accuracy and Reliability
Data quality profiling and validations are important components of data management in the retail sector. Profiling involves analyzing and understanding the structure and content of data, while validations ensure that data adheres to predefined standards. Together, they contribute to the creation of a robust data catalog and optimal results from data-driven initiatives such as the development of Machine Learning models.
In retail, where datasets with a lot of columns and records are the norm, data profiling and validations help to quickly identify inconsistencies and errors. This not only ensures the accuracy of product information but also aids in maintaining a consistent and reliable customer experience across all touch-points.
Synthetic data: A game-changer for Machine Learning in Retail
With the need to leverage as much data as possible, the timely access to the right data as well as data diversity play a huge role in the success of developing data-driven products. Synthetic data has shown to be a solution that plays a pivotal role in ensuring data quality to train and validate machine learning models in retail.
Synthetic data allows retailers to create realistic, yet artificial, datasets that mimic the characteristics of real-world data. This is particularly valuable when dealing with sensitive information or when real data is scarce. By leveraging synthetic data, retailers can enhance the performance of recommendation systems, optimize inventory management, and fine-tune pricing strategies.
Data Orchestration: Streamlining Retail Operations
Retail is an industry where vast amounts of data are generated on a daily basis from various sources such as online transactions, customer interactions, and supply chain activities. For that reason, efficient data orchestration and synchronization of these diverse datasets, is key to ensure that the strategies around the collection and preparation of the data are not only scalable but also accurate, versionable and comparable.
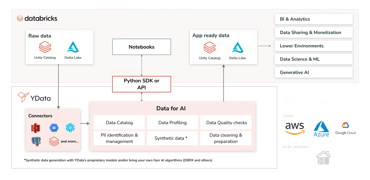
YData Fabric: The development environment for improved data quality
YData Fabric is a data development platform designed to expedite and enhance your AI initiatives. It empowered data teams with an environment that combines the benefits of automated data quality profiling, synthetic data and data pipelines to help you build some of the most common use-cases in the retail industry:
- Privacy-complaint customer analytics
Access to customer behavior data is often needed , such as preferences, purchase patterns, etc. Recurrent data pipelines combined with Synthetic data can not only ease the access to granular behavioral data information while preserving customers’ identities confidential. This supports the development of retail strategies that are more personalized
- Fraud detection in retail
Addressing fraud challenges in retail requires a holistic approach, due to its frequency of occurrence as well as evolutive behavior. Integrating automated data quality profiling, synthetic data augmentation that ensure more data diversity , and versionable data pipelines, enables the development of more accurate and robust fraud detection models that are able to handle evolving fraud traits at scale.
Conclusion
By prioritizing data quality, retailers can unlock new levels of efficiency, make more informed decisions, and provide customers with personalized and seamless experiences. As the landscape continues to evolve, integrating these data-driven strategies will be crucial for retailers aiming to stay competitive and relevant in the dynamic world of retail and e-commerce.
If you’re looking to accelerate AI development within your organization, start exploring Fabric Community where you can quick-start you in your journey towards data quality!
We have also a strong community that can help you throughout your journey. Join the Data-Centric AI Community to explore more materials and engage with other data quality enthusiast.