Synthetic data, designed to mimic real-world datasets, must be able to provide the same answers as real data to be valuable. For instance, when determining the average of customers that buy certain products, the result returned by the synthetic data should be similar to what would be obtained using the real data.
With this ability, the effectiveness of synthetic data to train machine learning models or create test sandboxes for AI development significantly improves, enhancing the reliability and value of data-driven pipelines.
In this article, we’ll shed some light on how Fabric evaluates the ability of synthetic data to provide the same insights as the original data when it comes to analytics and queries!
Can synthetic data provide the same answers as real data?
Fabric’s synthetic data PDF report uses a measure called QScore which returns a score in the [0, 1] interval. Higher scores indicate that the synthetic data is able to provide the same results as those obtained with real data, which translates into more dependable training sets and models that generalize better to real-world scenarios.
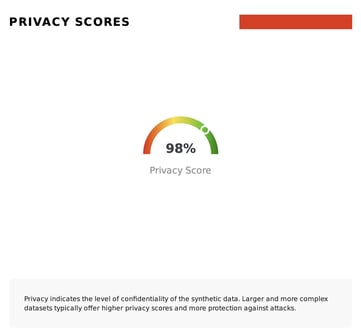
For industries such as finance and healthcare that often leverage Business Intelligence (BI) initiatives to gather summary statistics, demographics, and insights from the available data, achieving high values is crucial, typically above 0.8:

Conclusion
Synthetic data should be reliable at mimicking the original data value when it comes to answering similar queries. It’s crucial that the responses and insights we need to measure with synthetic are closely aligned with what you’d expect from real data.
Fabric’s synthetic data methods are able to generate high-quality synthetic data that keeps the original data insights. This means that the synthetic data is not just an approximation of the real data value, but a reliable source to retrieve the same information and derive the same insights as from real data. Naturally, this makes it a valuable asset for informed decision-making within your organization.
If you’re starting out with synthetic data, try Fabric Community and explore our synthetic data quality PDF report to check the full synthetic data quality metrics evaluated by Fabric.
Don’t hesitate to contact us for further questions or full access to the platform and feel free to join the Data-Centric AI Community for more learning resources.