Does it live up to the hype?
Nowadays, it’s said that we can quantify privacy or, even better, we can rank privacy-preserving strategies and recommend the more effective ones. Well, we can suggest something that goes even a bit further and allows us to design strategies that are robust even against hackers that have access to third-party information. And, as a cherry on top of the cake, we can do all of these things simultaneously, leveraging Differential Privacy, a method based on probabilistic theory.
...
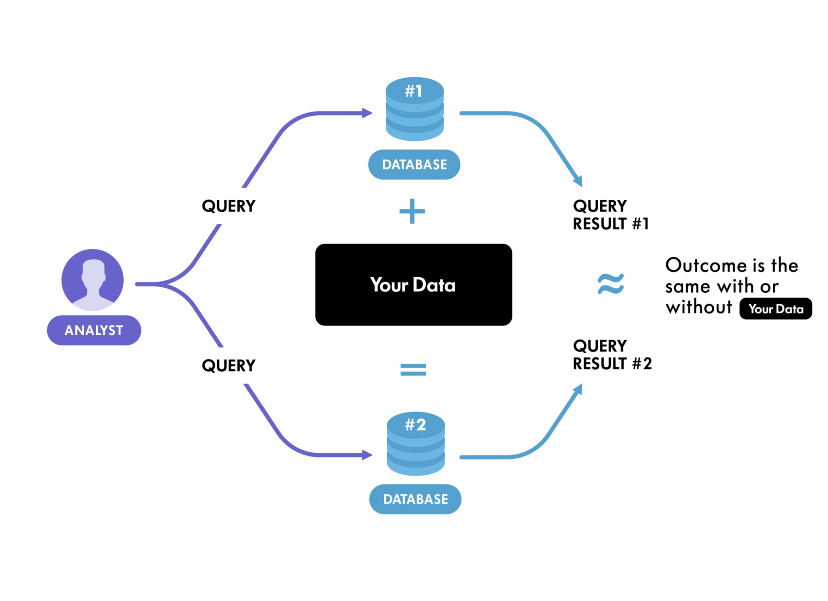
In general terms, Differential Privacy (DP) is a mathematical definition of privacy in the context of Machine Learning and Statistical analysis. It was originally proposed by Dwork, Nissim, McSherry, and Smith and was further developed by many other researchers. Roughly speaking, Differential Privacy guarantees that anyone seeing the result of analysis (with DP enabled) will essentially make the same inference about any individual’s private information, whether or not that individual was included in the input data.
First of all, we need to know what is private information and what is not. In the context of DP, the information that is specific to an individual in the population is called private information. On the other hand, information that is not specific to any particular subject but true for the whole population is called general information. Let’s take a simple example to understand this concept. Suppose Bob who is an alcoholic is taking part in a survey that studies the relationship between alcohol intake and liver cancer. After analyzing the survey data it is found that excessive alcohol intake causes liver cancer. According to DP, no private information about Bob is revealed because the result of the survey (impact of alcohol on the liver) is independent of whether or not he was in it. The conclusion of the survey is treated as the general information of the population, not as the private information of an individual.
But you’re probably thinking, if I decide to anonymize or remove any PII information regarding Bob, I can also ensure privacy right?
Well that's not entirely true, if somebody knows the alcohol intake habit of Bob and the result of the survey then he/she can question the health condition of Bob, for example. So clearly, the survey can still reveal some PII information about Bob.
But in reality, how hard is it to breach privacy?
Long story short, if you hold any auxiliary information from other data sources, anonymization is never enough. A widely known case was when, in 2007, Netflix released a dataset of their user ratings as part of a competition. So, the question resides - how can we ensure privacy, knowing that private means protecting the data from an adversary that holds information from the outside world that can help him attack the data? Let’s find out!
What is DP after all?
Differential privacy — Winton research
Now that we already understand the problem that DP based-mechanisms proposes to solve, let’s see how they work in reality. Again, let’s assume a survey containing ‘yes’, ‘no’ questions. The survey asks some controversial questions so the information about the participants should not be revealed. Differential privacy can be implemented by the following steps.
- Flip a coin;
- If heads then record the original response;
- Else, flip the coin again;
- If heads then record ‘yes’, else record ‘no’.
Because of the coin flips, we are introducing randomness in the responses. This introduced noise ensures privacy. Essentially, we are making a trade-off between accuracy and privacy. If the probability of getting head is 1 then always the original response is recorded, and no noise is introduced so accuracy will be high but there will be no privacy. If the probability is 0 then the responses will be random and noise (thus privacy) will be maximum but the data will be of no use. So, we have to pick the value of the probability such that we ensure privacy without sacrificing too much accuracy.
The privacy budget
It sounds like a fancy name, but it’s quite easy to understand: privacy losses are cumulative. This cumulative property is a direct consequence of the composition theorem. In a nutshell, with every new query that is made to a database, additional information about the sensitive data is released, hence the pessimistic view of the composition theorem, where the worst-case scenario is assumed: the same amounts of leakage happens with every new response. For strong privacy, we want the privacy loss to be minimum.
While leveraging Differential Privacy, and knowing that privacy losses are cumulative, data curators should enforce a maximum privacy loss — the privacy budget.
The pros
- DP provides a mathematically provable measure of user privacy. It guarantees that the result of a survey is independent of the presence of any particular individual;
- DP can be used as a defense mechanism against many types of attacks for example reconstruction attacks, linkage attacks, etc.;
- DP ensures stronger privacy for bigger datasets — the bigger the better.
The cons
- The more information (more queries) we need to gather from the database the more randomness needs to be introduced to minimize privacy leakage. Due to this randomness, complex Machine Learning models will get harder to train;
- In some cases, DP can treat the information as general which might be treated as private information by an individual. So, it’s very important to decide beforehand which information is general and which is private to reduce harm to that individual.
- DP only works on huge datasets. For a small dataset, DP produces poor performance because the addition of randomness will make the data so noisy that it would be impossible for a model to learn from it.

Facebook leveraged DP to share data with external research entities
Some companies are already leveraging DP, and some of them are even using it to share data in a privacy-preserving manner with external entities. For example, in 2018, Facebook leveraged DP to share its data with a community of researchers, nevertheless, it seems like not everything went smoothly — one year later the project was in trouble due to the poor quality of the data, as reported by the Science Magazine and the New York Times. And this is not surprising, as in any DP-based system it’s very hard or even unlikely to get decent analytics if strong privacy is being enforced. With privacy and data utility everything is a trade-off.
Some DP open frameworks
IBM differential-privacy
IBM’s open-source DP library comes with 3 modules — Mechanisms, Models, and Tools — and is developed specifically for python3. You can check IBM’s repository.
Tensorflow-Privacy
If you are looking to develop your machine learning models in a differentially private manner, Google’s launched Tensorflow Privacy in March 2019. This is an open-source library that eases the life of developers that are looking to ensure strong privacy for their Machine Learning models, making them more robust to attacks.
Pytorch Differential Privacy
Similarly to Tensorflow-Privacy, Facebook also released an open-source library that enables PyTorch model training with DP, with few changes in the code. You can check the repository.
Conclusion
The amount of sensitive data collected from users is increasing rapidly. With the new data collection methods in online shopping, navigation, transactions, movie recommendations, etc., the risk of privacy violation is more than ever. Differential Privacy is a promising technology to tackle this situation. It will allow companies to perform data analysis without sacrificing user privacy, nevertheless bear in mind that DP is still not able to replace the use of real data for ML-based solutions.
DP is still an active field of research and we are expecting to see new DP techniques in the future. However, tech giants like Google and Apple have already applied differentially private algorithms on their user data which clearly shows us the potential of DP.