If you haven’t heard it yet, here’s the latest news: the Data-Centric AI Community is organizing regular collaborative coding sessions, called “Code with Me”.
In our most recent session, we delved into the exciting world of Large Language Models (LLMs) and built a Multi-Document LLM App in under an hour, leveraging popular open-source packages such as llama-index and langchain.
Don’t believe us? Let’s walk through the main steps that showcase our journey in building thins innovative application!
From Zero to Hero: Querying Multiple Documents
LLMs have gained significant attention in the field of Natural Language Processing (NLP) due to their ability to comprehend and analyze information from multiple sources. In this session, we explored a practical implementation of a Multi-Document LLM App, which enables us to extract insights from a collection of documents!
For our coding session, we utilized the following python tools and libraries:
- llama-index: A library that provides advanced indexing and retrieval capabilities.
- langchain: A library for connecting and composing various NLP models.
- nltk: Natural Language Toolkit for essential NLP tasks.
- openai: Fo integration with OpenAI's language models.
- milvus: A vector similarity search engine.
- pymilvus: A library to interact with milvus
- python-dotenv: For managing environment variables.
Then, we built our LLM App in 5 main steps:
- 1. Starting the Code — We kicked off our coding journey by installing the required packages and downloading the NLTK stopwords (we’ll need to create decomposable queries). We then proceeded to set up the OpenAI API key and create a Milvus vector store for efficient document indexing and retrieval.
- 2. Data Collection and Preprocessing — Our Multi-Document LLM App focused on analyzing information from Wikipedia articles about several cities. We collected data by querying Wikipedia's API for relevant articles and storing the extracted text in individual files.
- 3. Building the LLM Index and Creating a Composable Graph – Then, to harness the power of multi-document analysis, we built a GPT-based vector index for each city's document collection using the llama-index library. And in order to enable efficient keyword-based retrieval and comparison, we created a composable graph of indices using ComposableGraph.
- 4. Query Transformation and Engine – Then, to enhance query understanding and retrieval, we implemented a query transformation pipeline using DecomposeQueryTransform and added a few custom query engines for individual city indices.
- 5. Running Queries – Finally, we put our Multi-Document LLM App to the test by running queries that involved comparison and summarization of airport information from different cities!
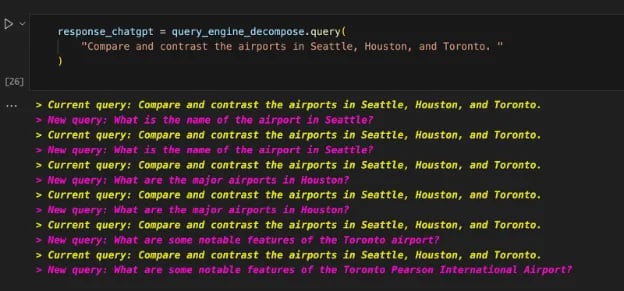
Running queries in our Multi-Document LLM App
Could not attend? We've got you covered
Attending the live session is always better for discussions and interactive Q&A directly with the code master! However, we know that life gets in the way sometimes, and we wouldn’t want you to miss out on anything!
You can find catch the full recording on our YouTube channel, where we break down each step and offer insights into the code:
And for those eager to dive right in, you can find the complete code on our Github repository, ready for you to experiment and explore.
Conclusion
The community has spoken and we heard it loud and clear! AI is moving so fast that sometimes is hard to keep up with all the new technology coming out daily!
Our Code with Me sessions are an informal way to pick on a topic and explore it together, in a low-pressure and collaborative environment. This time, we focused on a hands-on experience in building a Multi-Document LLM App using advanced indexing, query transformation, and powerful language models.
What will be next?
Well, that’s up to you! Join us on the Data-Centric AI Community server and let us know what other topics you would like to see unveiled!
We look forward to welcoming you to our upcoming sessions, where we'll continue to unlock the magic of technology together. Whether you're a seasoned coder or a curious newcomer, you always learn something new and get to meet awesome people!
Cover Photo by Mariia Shalabaieva on Unsplash



