Get started with Synthetic Data Generation with these Open Source Libraries
Following the extraordinary advances of Generative AI models, Synthetic Data is becoming the standard for Machine Learning development. Especially with the rise of Large Language Models (LLMs), synthetic data will prove transformative in the upcoming years, and it’s predicted to overshadow real data by 2030 completely.
As data scientists, it’s about time that we keep a sharp eye on this.
Our frustrating days of squeezing out the most information from a limited, dirty set of data — or waiting for data-sharing and privacy regulations to get approved — might just be coming to an end. Good news, right?
Yes, they are. Yet, the growing interest in Synthetic Data within our organizations raises a number of questions, not only ours as the ones developing the models or analyzing the data, but also from stakeholders, domain experts, clients, and business parties.
The overarching question underlying all of these is: How does it work? Can we rely on it? Can we really use it? Can we trust it?
Trust naturally arises from experience: from exploring and working with a topic so extensively until we fully grasp it, inside and out.
The more we experiment with synthetic data, the more clear its generationprocess, applications,benefits and limitationswill become. And the more empowered we will be to efficiently leverage it and tweak it to our needs.
Cue the wonderful world of Open Source Software!
In this article, we’ll review the top 5 Python packages for synthetic data generation currently in everyone’s mouth: ydata-synthetic, sdv, gretel-synthetics, nbsynthetic, and synthcity.
They will help you get started with the internal workings of synthetic data and allow you to master the art of the “fake it, till’ you make it”.
1. ydata-synthetic
ydata-synthetic comprises the most extensive set of strategies to get you started with synthetic data generation. The top-notch methods currently include CTGAN for conditional tabular data generation, TimeGAN for time-series data, and a GMM-based model for those that want a fast but efficient synthesis without the need for a GPU.
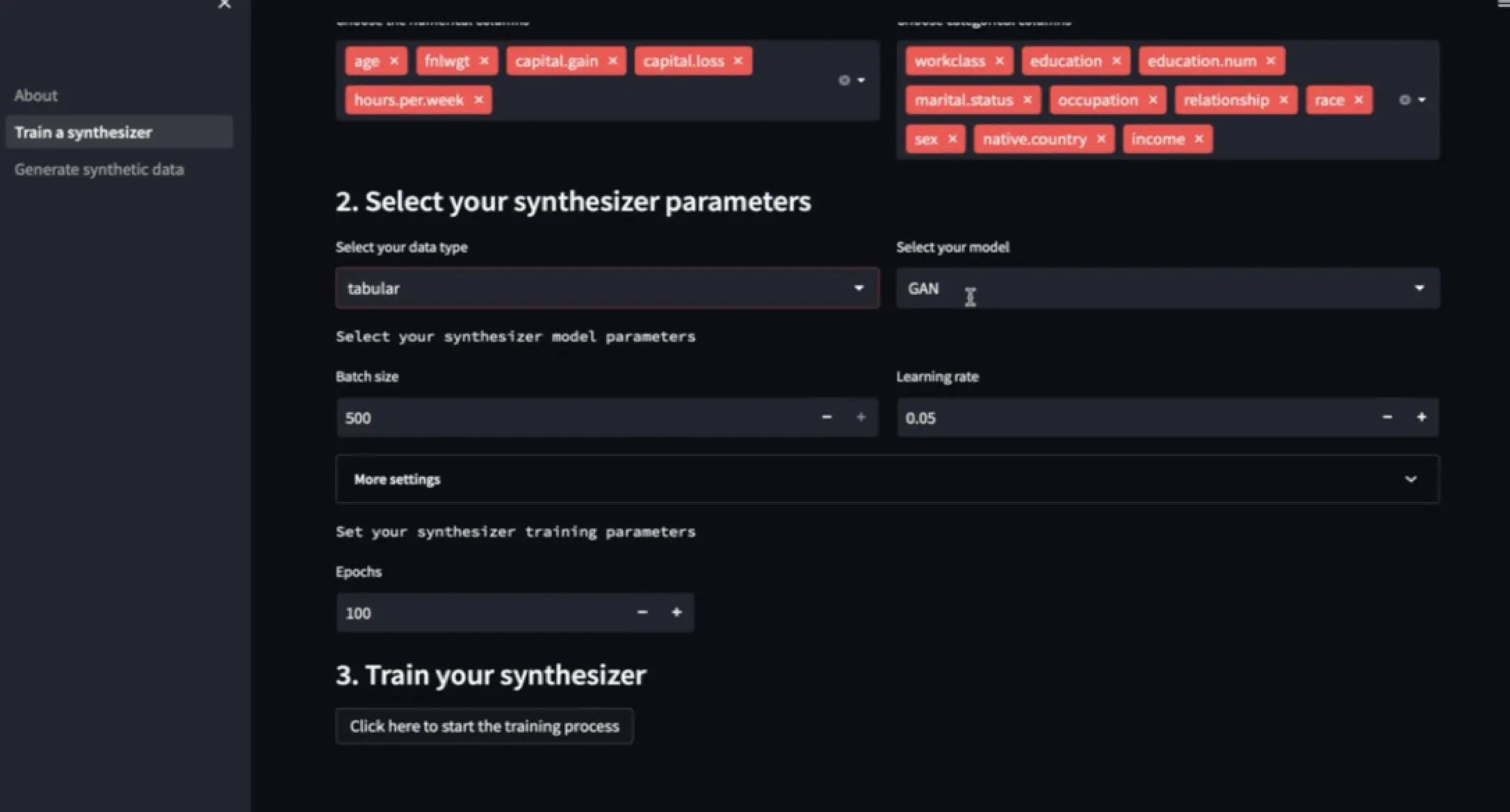
One of the “chef’s kiss” functionality is the GUI experience, powered by a Streamlit App.
Available since version 1.0.0, the new Streamlit app lets you conduct a complete synthesization flow from reading the data to profiling your generated synthetic data (bonus points: you don’t need to be an expert to start exploring synthetic data for your applications!).
ydata-synthetic: Streamlit App. Screencast by Author.
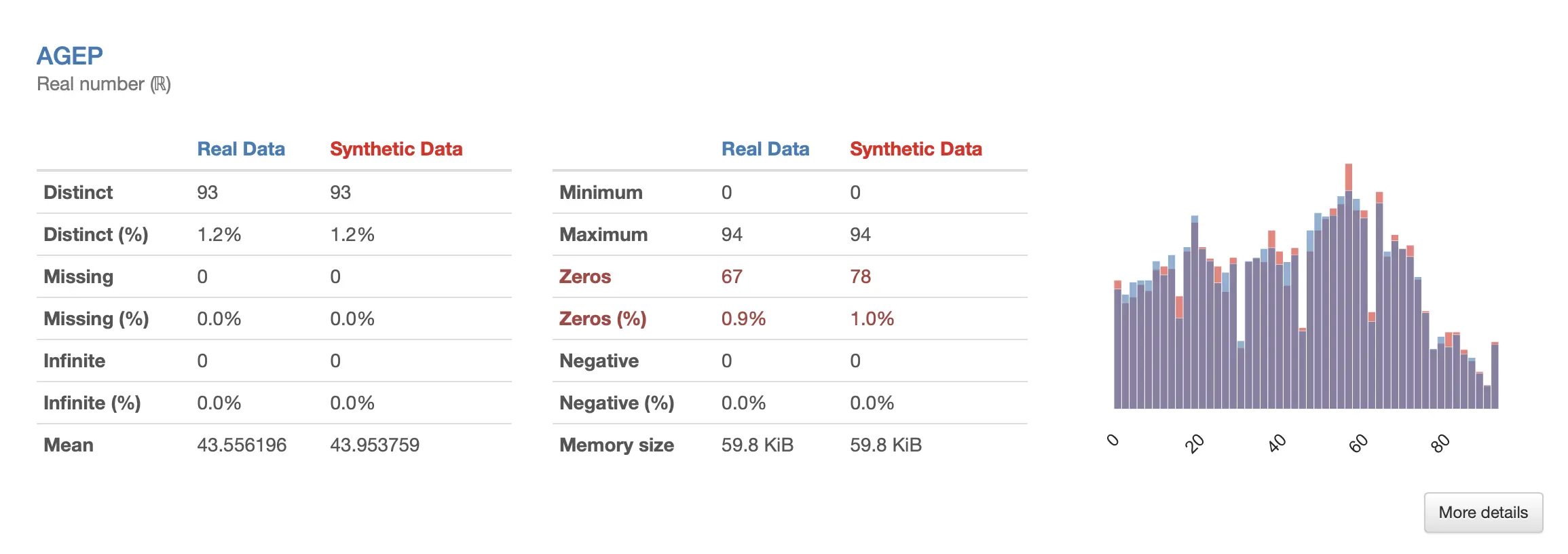
ydata-synthetic further integrates seamlessly with the data science stack, including ydata-profiling, where the real data can be matched against the synthetic data via the comparison_report feature:
ydata-profiling: Comparing real and synthetic data. Image by Author.
Overall, the project has a strong educational component and is extensively oriented to support the data science community, having it’s own community server where collaborators can interact directly with the development team and discuss new features and interesting applications.
2. SDV
The sdv package explores a different variety of synthesizers, from classical ML algorithms (e.g., Gaussian Copula) to GAN-based models or Variational Autoencoders, and handles both single table and multi-table data.
The most welcomed functionalities are the anonymization control and the application of constraints for the generation of synthetic data. The metrics report is also useful to get an understanding of the data quality.
sdv: Comparing the properties of real versus synthetic data. Image from SDV project.
Overall, sdv is part of a larger ecosystem for synthetic data (the Synthetic Data Vault Project). This means that we can either use each available package as a standalone solution, or incorporate them as complementary flows, which is a nice asset of the project.
3. gretel-synthetics
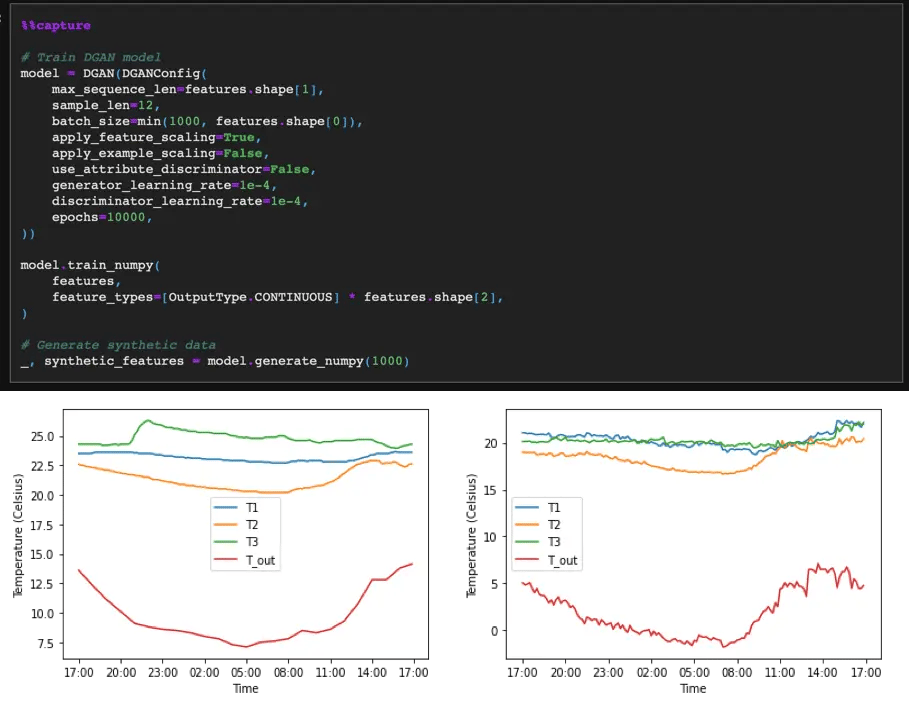
gretel-synthetics leverages popular models such as an LSTM-based architecture for synthetic data generation, Time-Series DGAN, and ACTGAN.
The package offers flexible customization options for data generation, although for someone starting out in the field, it might not be the most intuitive package to explore, as there are certain dependencies that need to be separately managed depending on the modules we intend to use, plus an extensive set of additional configurations that may make us feel like we’re somewhat going down the rabbit hole:
nbsyntheticfocuses on tabular synthetic data generation using an unsupervised GAN architecture, and is intended primarily for small and medium-sized, mixed datasets (comprising numeric and categorical features).
The ability to produce stable and robust models for small data is an interesting twist to the previous packages.
Synthetic data generators are generally designed to crunch large datasets (the more data, the better). Yet, theproblem of small data is known to be a complicating characteristic in real-world domains: when the training set is not enough, machine learning models fail to adequately learn the decision boundaries between class concepts, or the overall properties of data for that matter (which impacts synthetic data generation).
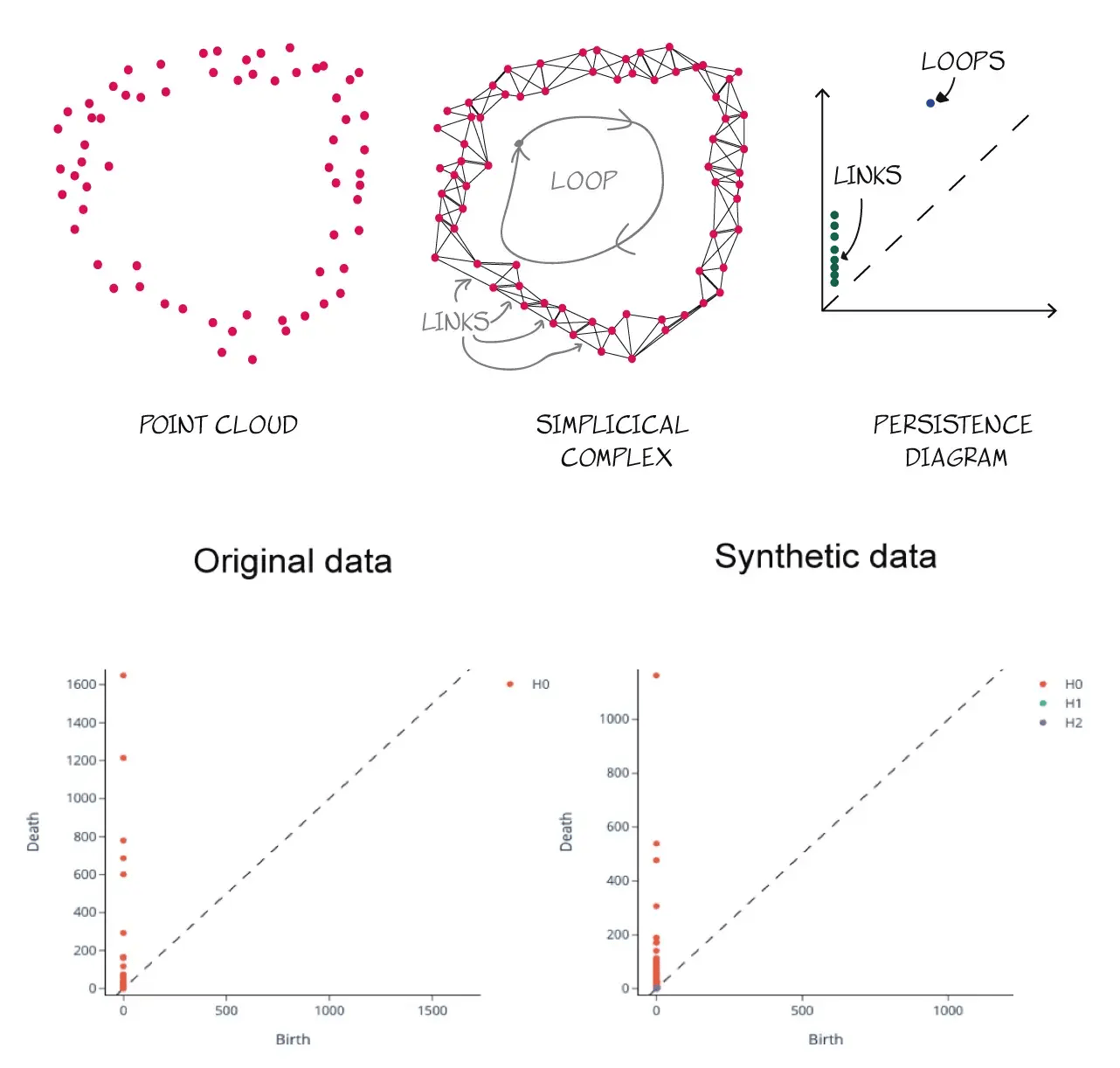
Another interesting take is the use of Topological Data Analysis (TDA) to compare real and synthetic data.
The package considers a standard module for statistical tests and some plotting utilities to compare and evaluate real and synthetic data, but TDA is a rather novel approach, where the distances and clusters in real and synthetic data are used to produce a topological footprint of each dataset, whose similarity can then be compared:
nbsynthetics: Comparing original data against synthetic data focusing on TDA analysis. Image by Javier Marin in TDS Medium.
5. synthcity
An up-and-comer in the field is also synthcity, which includes a diverse collection of methods for synthetic data generation, from general purpose GAN- and VAE-based models for tabular and time-series data, to more privacy-, fairness-focused, or domain-specific models (namely for survival or image analysis).
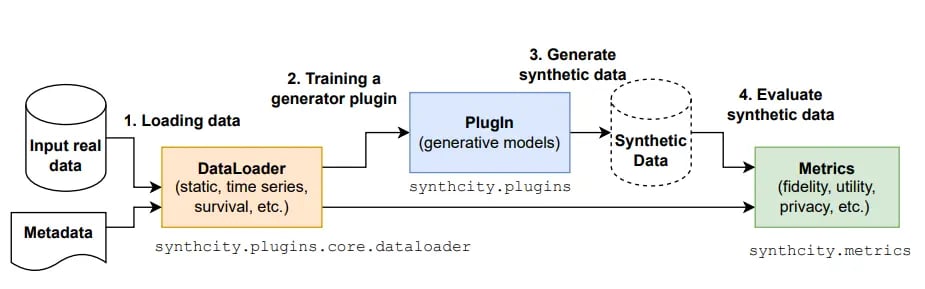
synthcity also comes with a built-in module for synthetic data evaluation, including privacy metrics, which offers a nice complete flow of data synthesization:
synthcity: Standard workflow for generation and evaluation of synthetic data. Image by Qian et al. on ArXiv.
While the documentation is currently under development, there are several of available examples in the project’s GitHub repository, and a quite extensive list of research references, which is useful to learn more about the implemented methods and other additional details.
Final Remarks
In this article, we’ve discussed the top 5 synthetic data generation tools available in open source, highlighting their strong points and applications.
From an educational standpoint, I’m always looking for packages with a solid documentation and examples, as well as smooth entry points for beginners, for which ydata-synthetic has been thriving, especially with the Streamlit experience. Nicely done.
Yet, in all fairness, there’s no magic tool that bests all others.
Your tool of choice will depend on your use case, computational requirements, expertise, and personal preference (e.g., coding style, customization, structure).
Ultimately, you’re best served by combining the core points of each one, and baking your cake without restrictions.
What if I don’t have a real dataset to generate data from?
— You might be wondering. Here we’ve covered data-driven synthetic data generation packages, but there are other OSS packages out there that let us create “fake” data for different use cases. But that, my friends, is for another article!
Looking to learn more about synthetic data with some hands-on projects?
You’re in luck. The Data-Centric AI Community has recently launched a small community project for beginners to experiment with Synthetic Data. The instructions are given on a weekly basis, questions are posted on our dedicated discord channel, and we meet regularly to discuss our findings and solve issues together. Join us and stay up-to-date with the upcoming projects!