Exploring TimeGAN and YData Fabric for Synthetic Data Generation of Temporal Patterns
In order to accelerate AI development and guarantee the best business practices and results, organizations rapidly need to become more data-centric. Quality and reliable data is the backbone of accurate decision-making but it can be expensive to collect or impractical to share, due to the privacy aspects associated.
For this reason, synthetic data has become a central topic with organizations: as it replicates the properties of real-world data, it can boost AI development in several ways, from data augmentation or model training and testing to data-sharing and privacy protection.
Especially with the widespread evolution and adoption of Generative AI, the process of synthetic data generation became even easier for the wide data-science community, but how does it apply to real-world domains?
What are the challenges associated with Sequential, Time Series Data?
Although tabular data may be the most frequently discussed type of data, a great number of real-world domains — from traffic and daily trajectories to stock prices and energy consumption patterns — produce time-series data which introduces several aspects of complexity to synthetic data generation.
Beyond the temporal dependency between records, time-series datasets have many other properties that introduce complexity to the process of generating synthetic data.
Time-series data can exhibit a wide range of patterns and trends, including seasonality (patterns that can be repeated at calendar periods – days, weeks, months – such as holiday sales, for instance) or periodicity (refers to a pattern that repeats itself over time).
Additionally, depending on the use case or downstream application, the time-series synthetic data generation process may need to attend to different aspects. So, what is the best method to generate synthetic sequential data? Do existing methods apply to your desired use cases? What requirements can be addressed by open-source solutions like ydata-synthetic and when do you need to move towards more specialized solutions such as YData Fabric?
TimeGAN architecture - The benefits and limitations
One of the most popular generative AI models for time-series synthesization is TimeGAN, which stands for Time-series Generative Adversarial Network. However, when starting with time-series synthetic data, users find themselves intrigued with the internal working of this architecture:
- Is TimeGAN adequate to replicate the entire temporal such as daily values of a full year?
- What does TimeGAN expect as input? How must data be preprocessed for synthetic data generation?
Essentially, this architecture is strongly based on the concept of “windowing”. Each “window” (or “frame”) represents a time sequence of a defined length that the model learns to mimic.
To showcase the architecture, we’ll use the Yahoo Stock Price. Consider the “Volume” attribute, which represents the total amount of trading activity per day:
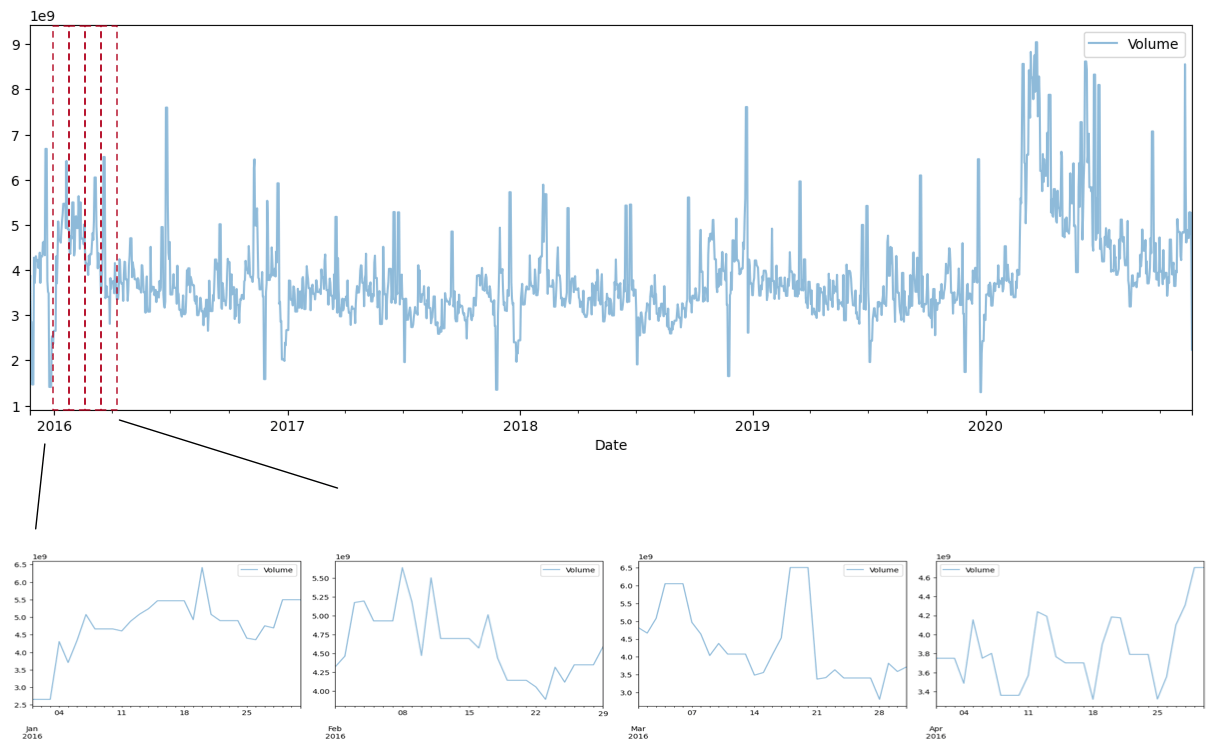
Time frames of the first 4 months of 2021
The overall time series can be "broken down" into time frames, or windows, each respecting a specific time length. In the image above, we're considering 30-day windows that represent the first 4 months of 2021.
This architecture specializes in learning the patterns and trends in short frames of data: it can map the data distribution of short-term patterns. But given the way the architecture was conceived, the relations and temporal dependency between windows are not ensured and for that reason, TimeGAN is not designed to replicate both short-term and long-term temporal patterns. This means that the architecture is not suitable to recreate an entire temporal series, but it can accurately learn the diversity and distribution between the time windows given as input:
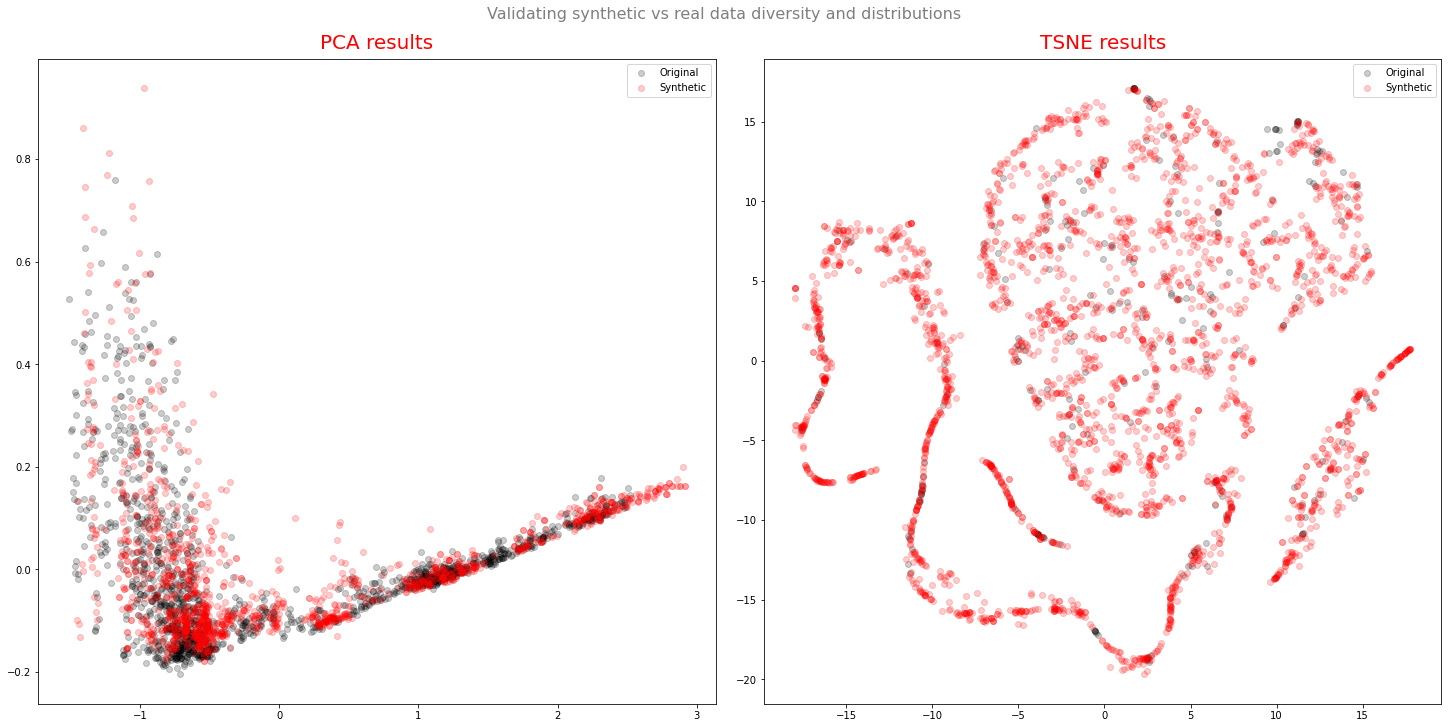
Validating synthetic vs real data diversity and distributions
Due to the explained behavior, the architecture can be extremely interesting for data augmentation, increasing the representation of underrepresented time windows. For instance, one application could be augmenting the representation of certain seasonal shopping trends (e.g., Black Friday), so that the machine learning models are able to learn these patterns more effectively.
Let’s imagine that we needed to improve the representation of April’s 2016 trends. TimeGAN could be used to generate several synthetic time windows corresponding to the desired period:
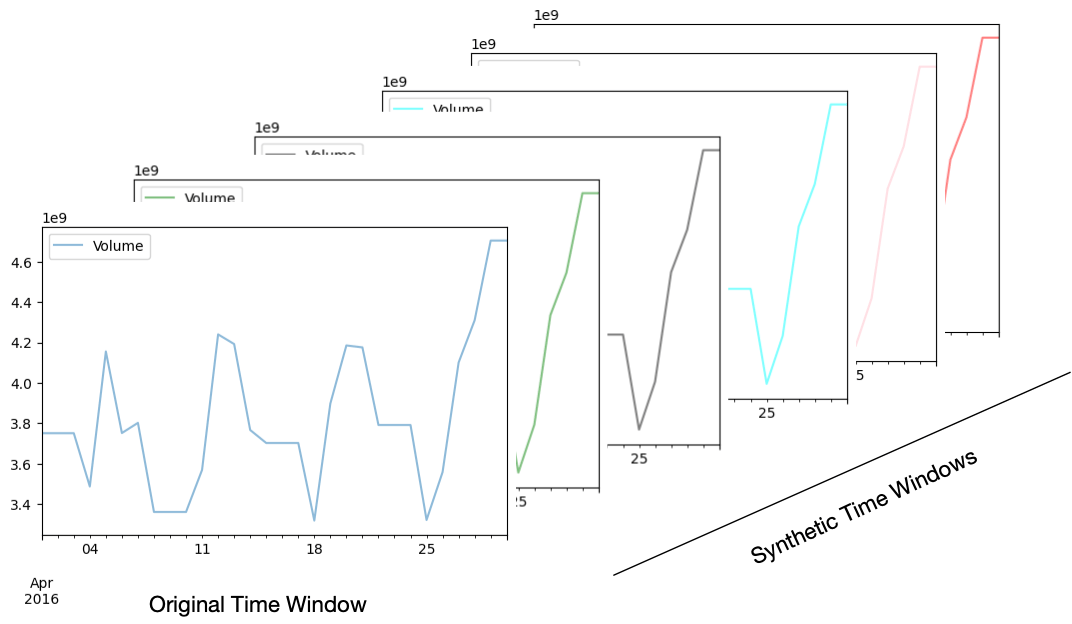
Representation of synthetic time windows
Similarly, the synthetic data can also be used for privacy protection and data-sharing purposes, as long as the reconstruction of the full original data’s time sequence (i.e., keeping both short and long term patterns) is not part of the requirements.
TimeGAN has other challenges beyond the ones covered so far. As almost all deep learning algorithms, it is data savvy and therefore it will require large amounts of data to appropriately converge. Additionally, it may struggle with the generation of tails and spikes in the time sequences if it is not properly tuned in terms of parameters such as sequence and batch size.
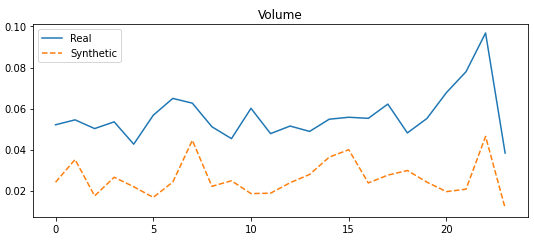
Real vs Synthetic Data for Volume feature
Also, due to the complexity of the architecture, it can be hard to optimize and adjust to a large range of datasets with different characteristics and its training process can be quite computationally expensive and time-consuming.
Nevertheless, and regardless of these challenges, TimeGAN has proven to be one of the best Generative models out there for the generation of sequential datasets with high variability.
But you might be wondering: “Are there any other models best fit to replicate both short and long-term time-series trends, keep the original data structure, and that can be easily adjusted to my downstream application?”.
If you need a more flexible model that can be applicable to a wider variety of datasets and use cases, you'll need to move to different architectures, such as those built in YData Fabric.
How does YData's Time-Series Synthetic Data Generation compare to TimeGAN?
YData Fabric offers a flexible and reliable solution for time-series synthetic data generation that allows to replicate both short-term and long-term temporal correlations embedded in the data, meaning that it can replicate and reconstruct the full time sequence that some use cases require.
Since the YData’s time-series synthesizer is designed to replicate the entire temporal series taken as input, the original time horizon is respected and the output is a synthetic time-series sequence with the same length as the original data.
The YData’s synthetic data generation model learns over a larger period/sequence of time events and it is capable of generating high-fidelity time-series datasets that replicate the time patterns and data behavior and distributions, even in the presence of mixed data types (categorical and numerical features).
Furthermore, the learning and generation of synthetic data are seamless for the end-use – there is no need to select the optimal sequence length for the training given a certain use case, or even tune hundreds of parameters, therefore being ideal for both data augmentation and privacy protection purposes.
The only requirements? Setting up the entity correctly in case you are dealing with a multi-entity dataset, specifying the columns that define the temporal order, and last but not least, choosing the desired privacy control for a better trade-off between utility and privacy, depending on the downstream application.
And there is an experience for all tastes! Since there are users that prefer a guided and straightforward training and generation of sequential time-series data, YData Fabric includes a UI experience in just a few steps.
For more advanced usage and flexibility, all YData’s synthetic data generation methods are also available through code at YData SDK.
If you’re familiar with Synthetic Data, you know how fidelity and privacy are two of the main pillars of synthetic data quality. With Fabric, you’ll be able to adjust whether your model is optimized for high fidelity (the default), for high privacy purposes, or considering a trade-off of both.
YData Fabric delivers more robust and flexible models for Time-Series Synthetic Data Generation
While TimeGAN is a great model for users to get started with time-series synthetic data, it is not a one-fits-all architecture. Due to the nature of TimeGAN architecture, it is hard to ensure the replication of short and long-term time correlations -- there is always a trade-off! Additionally, it is necessary to consider the complexity associated with the optimization of the architecture itself, which may require a significant amount of trial and error, besides being time-consuming.
YData Fabric offers more flexible time-series data generation models that overcome the limitations of TimeGAN and are more appropriate for a larger variety of use cases, including privacy protection.
Synthetic time-series datasets are extremely valuable for a wide range of domains and use cases, from forecasting and predictive analytics in financial services to anomaly and fraud detection on transactional bank data, or even simulation and modeling in the energy or transportation sectors.
These are critical applications where the quality of the synthetic data is crucial for high-performant machine-learning solutions and consequent competitive results.
Try out YData Fabric today and unlock the potential of high-quality time-series synthetic data!
For questions and troubleshooting, please find us on our Discord server for personalized support.
Cover Photo by Stephen Phillips on Unsplash