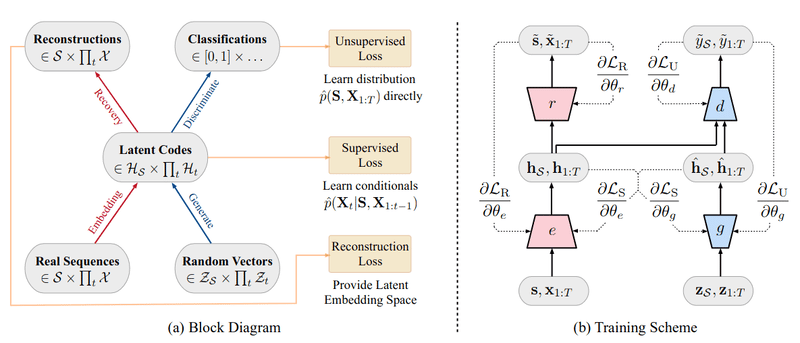
For the purpose of this example, I’ve decided to keep it simple with a very similar architecture for all the 4 elements: A 3 layers GRU network. But it’s possible to have this architectures change to more or less layers, and also to chose between GRU and LSTMs.
Which results in the definition of each of the networks elements as per the code snippet below.
In what concerns the losses, the TimeGAN is composed by three:
-
The reconstruction loss, which refers to the auto-encoder (embedder & recovery), that in a nutshell compares how well was the reconstruction of the encoded data when compared to the original one.
-
The supervised loss that, in a nutshell, is responsible to capture how well the generator approximates the next time step in the latent space.
-
The unsupervised loss, this one it’s already familiar to us, a it reflects the relation between the generator and discriminator networks (min-max game)
Given the architecture choice and the defined losses we have three training phases:
-
1. Training the autoencoder on the provided sequential data for optimal reconstruction
-
2. Training the supervisor using the real sequence data to capture the temporal behavior of the historical information, and finally,
-
3. The combined training of four components while minimizing all the three loss functions mentioned previously.
The full code detailing the training phases can be found at ydata-synthetic. The original implementation of TimeGAN can be found here using TensorFlow 1.
-
Synthetic stock data
The data used to evaluate the synthetic data generated by the TimeGAN framework, refers to Google stock data. The data has 6 time dependent variables: Open, High, Low, Close, Adj Close and Volume.
Prior to synthesize the data we must, first, ensure some preprocessing:
-
Scale the series to a range between [0,1]. For convenience, I’ve decided to leverage scikit-learn’s MinMaxScaler;
Create rolling windows — following the original paper recommendations, I’ve create rolling windows with overlapping sequences of 24 data points.
Following the recommendations from the original paper, I’ve decided to train the synthesizer for 10000 iterations nevertheless, bare in mind, that these values must the optimized for each data set in order to return optimal results.

Synthesizer training with 10000 iterations