Photo by Conny Schneider on Unsplash
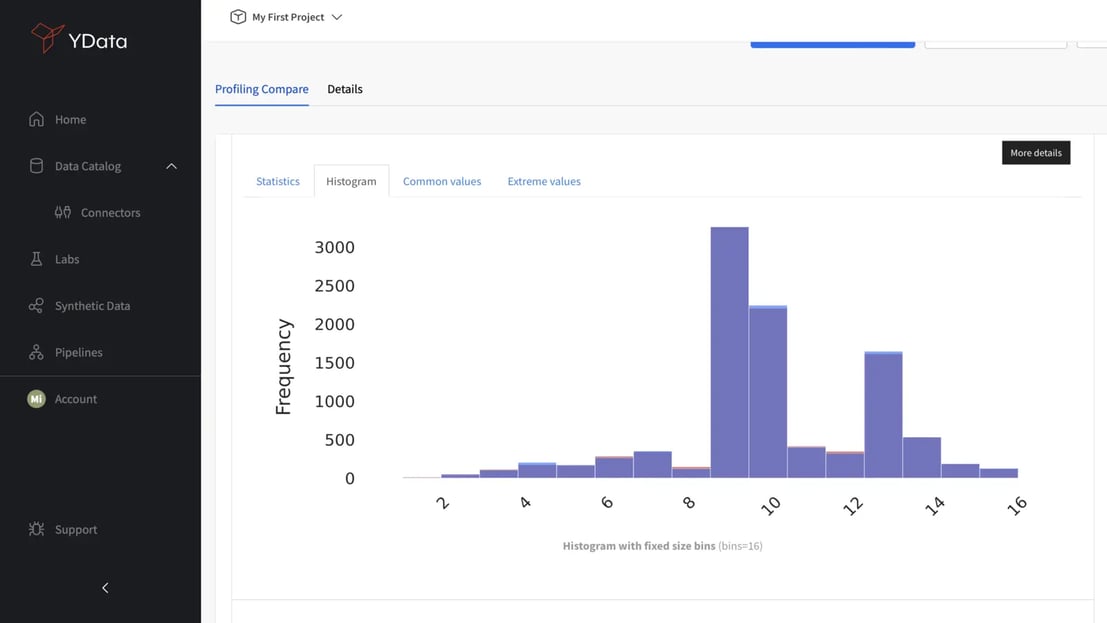
In the dynamic landscape of Data-Centric AI, data quality is crucial for the success of any analytics or machine learning initiative. Data profiling is an essential process that provides insights into the intricacies of your datasets, enabling informed decision-making. In this context, ydata-profiling emerges as the preferred tool for comprehensive data quality validation. It offers a robust solution to enhance the integrity and reliability of your data.
This research paper explores the potential of ydata-profiling and its features as a core framework for adopting a more Data-Centric AI approach. From providing an overview of the dataset's characteristics to conducting multivariate and automated data quality checks, ydata-profiling offers a comprehensive summary of your dataset's behavior. It serves as a valuable asset in your organization's Data Catalog.
Download this research paper to learn more about:
- The importance of standardized data quality profiling for the success of AI development
- The benefit of adopting an automated data quality profiling solution like ydata-profiling
- ydata-profiling compared to other solutions for data profiling