While allowing for meaningful data behavior, it is crucial that synthetic data safeguards individual privacy. Therefore, ensuring the efficacy of synthetic data applications also requires a strong assessment of re-identification risks.
Consider for instance an organization that wants to use synthetic data to train machine learning models using sensitive data. The challenge lies in achieving optimal results while also maintaining people’s records private and safe.
In a previous article, we covered how YData Fabric evaluates the privacy of synthetic data by determining the closeness between data points in synthetic and real data. In this article, we’ll focus more deeply on how to assess the re-identification risks associated with synthetic data.
What is the re-identification risk of my synthetic data?
To ensure that the synthetic data aligns with the privacy requirements of your specific use cases, Fabric’s synthetic data quality PDF report outputs the Identifiability Score, which indicates the likelihood of malicious actors using the information in the synthetic data to re-identify individuals in real data.
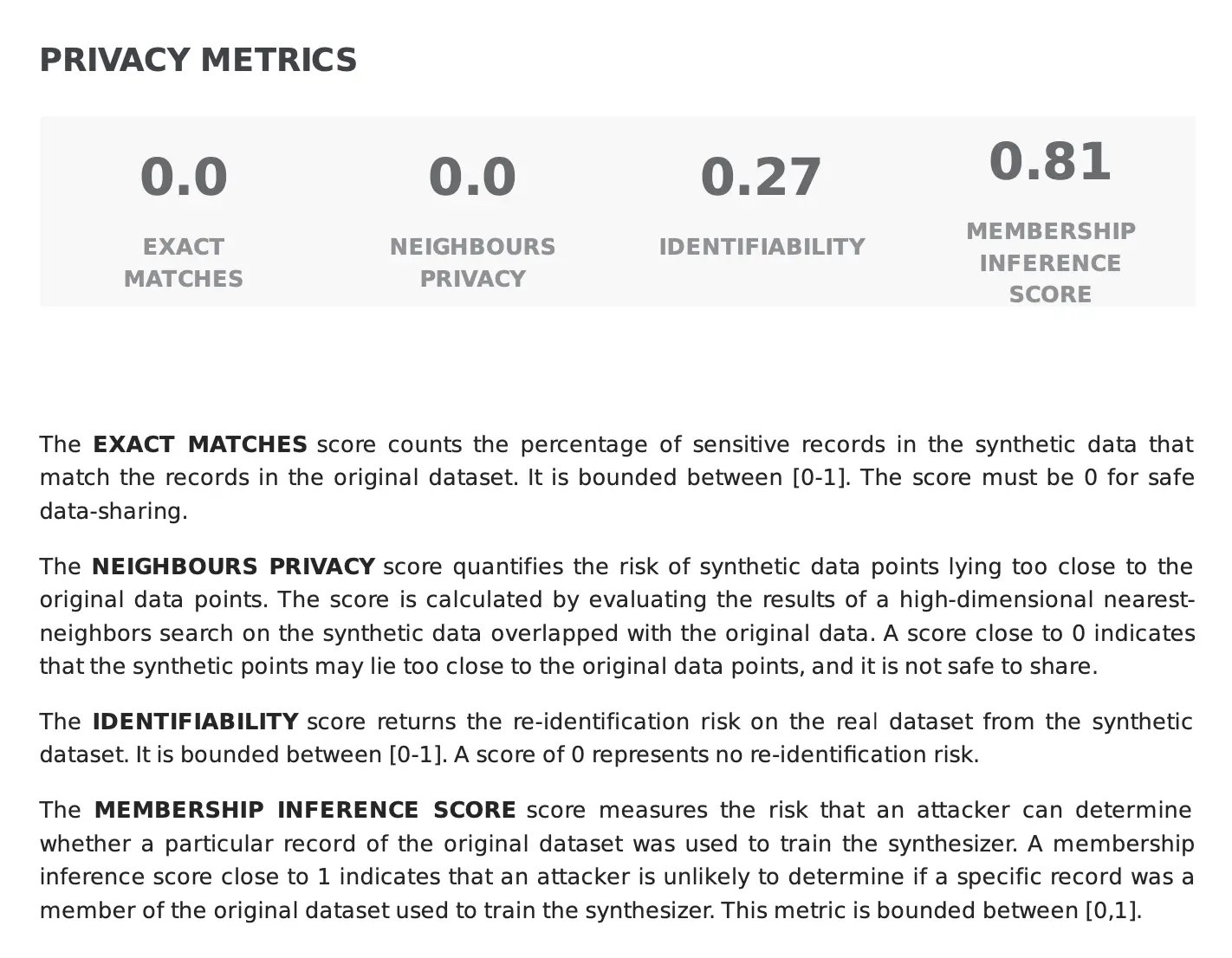
The Identifiability Score ranges from [0, 1], where a score of 0 indicates minimal risk, and scores closer to 1 imply a higher likelihood of re-identification. For instance, in the example below, the synthetic data returns an identifiability score of 0.27, indicating a low risk of re-identification.
How robust is my synthetic data to privacy attacks?
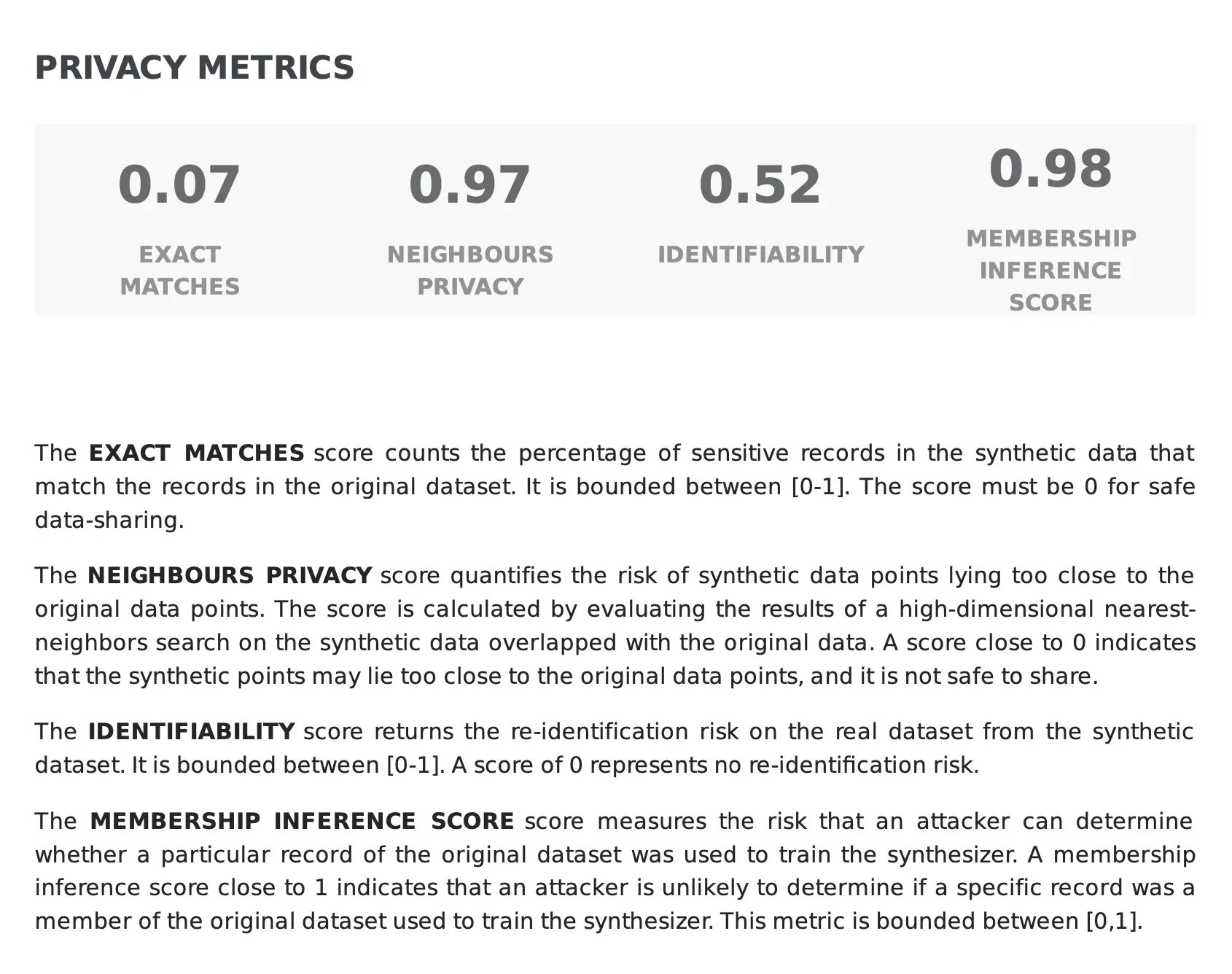
Beyond the risk of re-identification, there is also the possibility that a malicious attack can determine whether a particular record of the real data was used to train the synthesizer. Our synthetic data quality report measures such risk using the Membership Inference Score, also bounded within the [0,1] interval.
A lower score would suggest that the synthetic data is subjected to a potential private vulnerability and that the synthesization process may need to be adjusted to mitigate this risk. In turn, high scores indicate a robust level of protection against this type of attack, as indicated in the example below where the membership inference score is close to 1 (0.98).
At this point, you might be wondering “Which privacy metric should I take into account?” when evaluating the privacy of your synthetic dataset. In reality, these scores measure different privacy properties, and factors such as the chosen synthesis method and the characteristics of your real data contribute to each score differently.
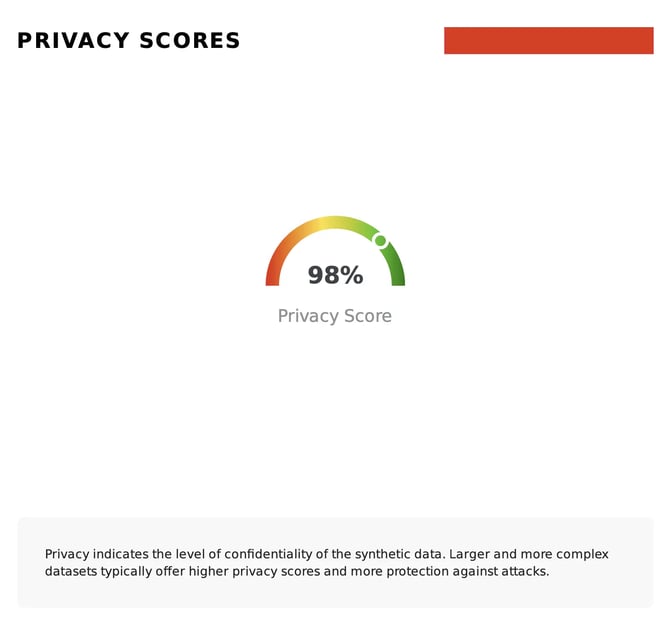
To guide the user through this evaluation, Fabric provides a global view of the privacy of the synthetic data by combining these privacy metrics into a single weighted score, which helps determine the suitability of your artificial data for privacy use cases. The example below shows this computation, where the synthetic data returns an overall privacy score of 98%, with a meter plot indicating a very good synthesization result: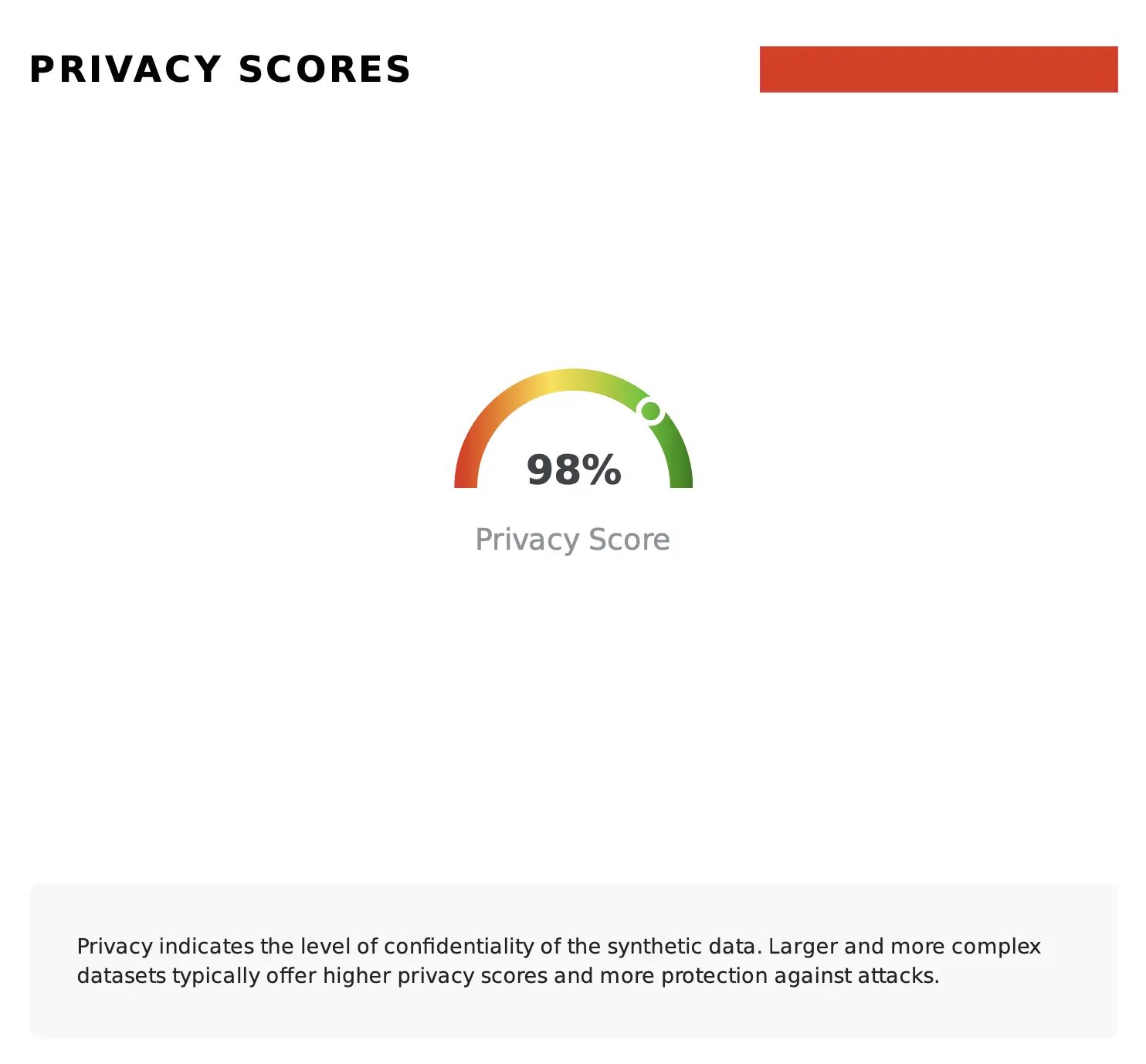
Conclusion
As organizations increasingly embrace synthetic data for various applications, the need to comprehensively evaluate the risk of re-identification becomes indispensable.
If you’re looking to leverage synthetic data for your privacy use cases, try Fabric Community to explore the available synthetic generation methods, or contact our team to understand how Fabric can help in your specific needs and use cases.