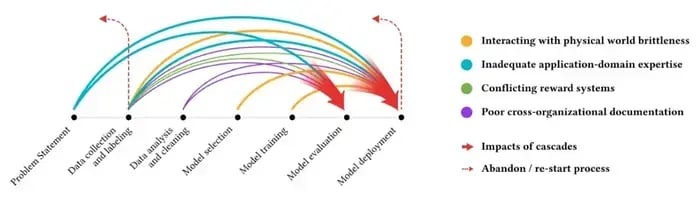
The stakes of data in AI development and success: source
The value of data and its impact on the quality of ML-based solutions have, for sure, been underestimated so far, but this is changing — inAndrew’s NG latest session, he covered the benefits of a bigger investment in data preparation with his team proving that investing in improved existing data quality is effective as collecting the triple amount of the data.
And that is what I’ll be covering today — the role of data quality in taking AI to the next level.
Same model, different data
As AI practitioners we are already aware of the elements that compose the development of a solution:
AI System = Code + Data, where code means model/algorithm
which means that in order to improve a solution we can either improve our code or, improve our data or, of course, do both.What is the right balance to achieve success?
With the datasets publicly available, through open databases or Kaggle, for example, I understand why the more model-centric focused approach: data in its essence more or less well-behaved, which means that to improve the solutions, the focus had to be on the only element that had more freedom to be tweaked and changed, thecode.But, the reality that we see in the industry is completely different. This was a perspective shared by Andrew NG with which I deeply agree —the model-centric approach has heavily impacted the available tooling available in the ML space for data science teams,until now.
Model-centric vs Data-centric
In my perspective, to achieve a good AI solution there’s a careful balance between what is called a model-centric vs a data-centric perspective, nevertheless, I’m conscious that the higher stakes of value remain on the data side. Happily, this perspective does not derive from a gut feeling, and to prove it Andrew NG and his team decided to show it with a couple of experiments with real-world data, but before that, let’s step back and define what means to bemodel-centricanddata-centric.
Thesteel sheets defect detectionwas one of the examples brought during the session — assuming a series of images from steel sheets we want to develop the best model to detect these defects that can happen during the process of steel sheets manufacturing. There are 39 different defects that we want to be able to identify. By developing a computer vision model with well-tuned hyperparameters, it was able to reach a76.2% accuracy baseline system, but the goal is to achieve90% accuracy.How can this be done?
Knowing that the baseline model was already good, the task to have it improved to achieve 90% accuracy sound almost impossible — for the model-centric, the improvements based on Network Architecture search and using the state-of-the-art architectures, whereas, for the data-driven, the approach taken was to identify inconsistencies and clean noisy labels. The results were mind-blowing:
The potential associated with shifting to a data-centric approach for not apply only to the computer vision realm, the same applies to other areas such as NLP or tabular and time-series data.
Why shifting from model to data-centric
Data has high stakes in AI development, and the adoption of an approach where achieving high-quality data is core is very much needed — after all meaningful data is not only scarce and noisy but also very expensive to be obtained. Just like we would care for the best materials to build our home, the same applies to AI.
The 80/20 rule for the data processing vs model training is widely known, nevertheless, we see a consistent focus in the model training step, which is reflected in the tooling that, nowadays, we find available in the market. To achieve a data-centric approach there are a few questions that we have to answer with the right framework, such as: Is the data complete? Is the data relevant for the use case? If labels are available, are they consistent? Is the presence of bias impacting the performance? Do I have enough data?
These questions are not expected to be answered at one single step of what is theML development flow, in fact, they are expected to be answered in an iterative manner, just like we would do if following a model-centric approach.
the data complete? Is the data relevant for the use case? If labels are available, are they consistent? Is the presence of bias impacting the performance? Do I have enough
But let’s focus on the last question —Do I have enough data?
This is a common one — in the era of Big Data, one of the main points for data quality was unmistakably volume- the bigger the better.But does this remain a single truth if we adopt a data-centric approach?
It’s very hard to be fully sure of whether we have or not a good amount of data, it is usually a matter of well my model is generalized when delivered into production. But, we have seen earlier in this blog post that, the better the quality of the data, the higher the probabilities of several models to do well.
Does this mean that quality matters more than quantity?
In a lot of the real-world problems, the reality is that not much data is available (healthcare, agriculture, fraud detection, etc), but that doesn’t mean those use cases are not suitable to apply machine learning —it’s all about how good and meaningful your data is.
The more data we have available the more noise it is present. Of course, if we have a lot of it, with the right hyperparameters and model choice we can achieve generalizable results, but how much performant and optimizable would the inference systems high-quality but smaller sets were chosen to train the models?To have cleaned and de-noised datasetswill become a key differentiator in data architectures, and to achieve them is where AI can also play a role —techniques such as semi-supervised learning can be very handy to identify and correct inconsistencies or synthetic data to produce and simulate more events to help in overcoming generalization problems.
From the infrastructure invested to have data collected, to the number of human resources dedicated to it and how rare can be to have it collected in the ideal situations, makes data one of the most expensive assets nowadays.
Data quality has to be monitored and improved at every step of the AI development, and which step will, inevitably use different frameworks and tools due to their nature.
And we must not forget, this has to be delivered and measured in a continuous manner which makesMLOpsa much-needed ally to achieve a proper and successful data-centric paradigm in the development of AI solutions.