Photo by Nemesia Production on Unsplash
In the current Data-Centric AI paradigm, where all businesses seek to leverage the power of their data for any competitive advantage they can get, organizations face a critical choice: to buy or build their solutions.
The landscape of synthetic data generation is no exception. The need to break data silos to accelerate development and data sharing while addressing data privacy concerns and compliance requirements has driven the demand for synthetic data solutions, with several open-source and proprietary solutions being continuously developed.
But when should your organization consider adopting a proprietary synthetic data solution over building one in-house or relying on using open-source alternatives?
In this article, we will discuss the differences between Fabric and the Synthetic Data Vault (SDV), a popular open-source solution among data practitioners, and discover how their functionalities compare across several components.
Fabric vs SDV: The Synthetic Data Arm Wrestle
Synthetic Data Generation Models and Supported Data Types
Organizations need to handle multiple sources of data with distinct characteristics, data complexity, categories cardinality, data size, and the presence of complex relationships. Finding a solution that can cope with distinct types of data and deliver optimal synthesization models is often a brain teaser:
- Optimized and Automatic Model Selection: Although Fabric and SDV share similarities in terms of used models, Fabric automatically optimizes the process of synthesization based on the metadata of the input dataset, reducing the effort and time of finding the model that best fit your business needs;
- Comprehensive Data Type Support: Fabric offers a higher versatility, with the ability to synthesize data across a wide array of data types, including tabular, time-series data (univariate and multivariate), transactional data with intricate time relationships between entities, and relational databases. SDV falls short, struggling to replicate more intricate data patterns;
- Explainability and Compliance: Beyond deep learning-based models, Fabric further incorporates other learning paradigms, which provide more explainable outcomes for highly regulated industries, following the best practices of Responsible AI development.
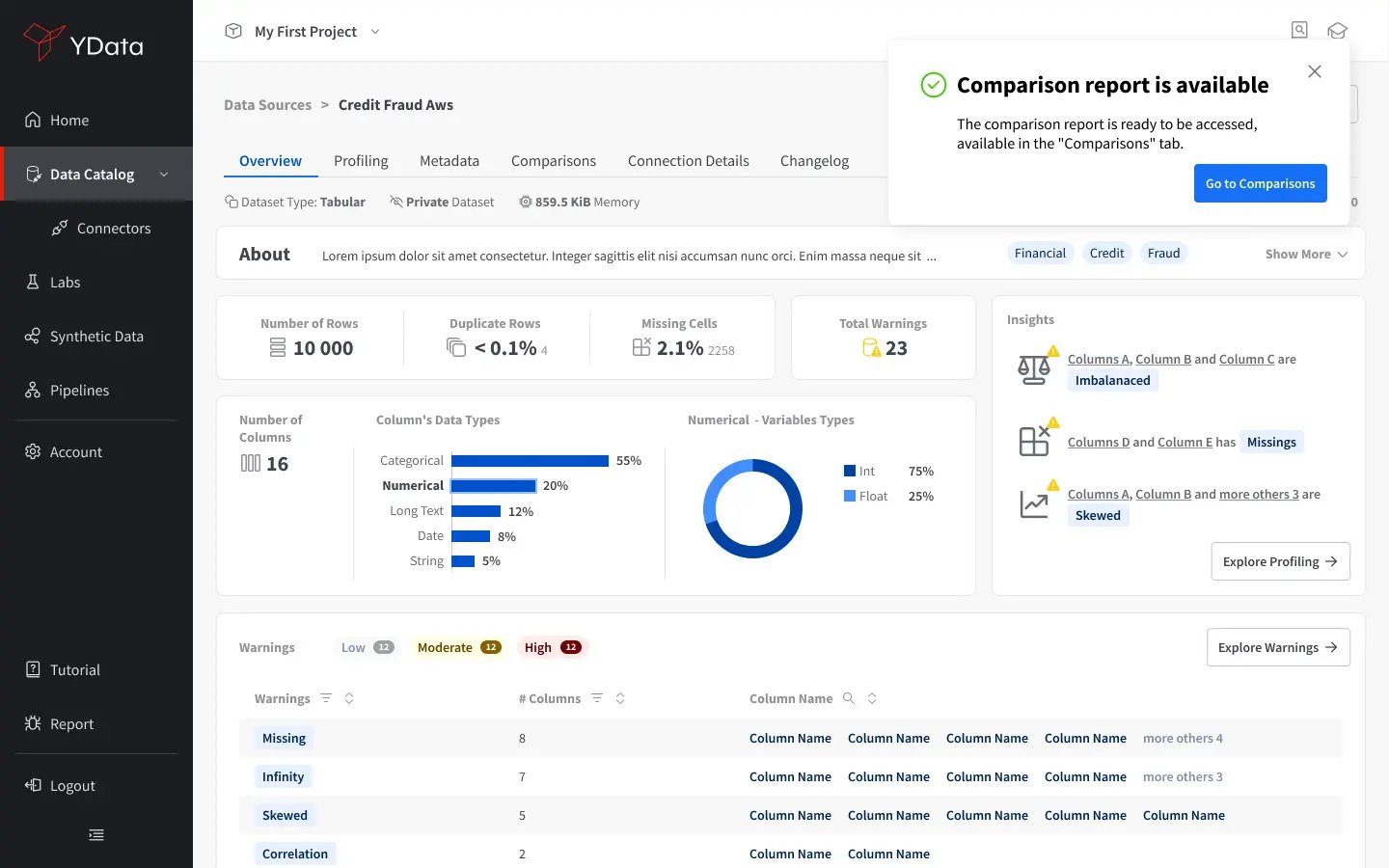
Business and Privacy Controls
For organizations, having the ability to set business rules and constraints, as well as ensuring data privacy, is paramount.
- Customizable Synthetic Generation: SDV explores model tuning and hyper-parameter selection irrespective of your business needs and constraints. On the contrary, Fabric follows a business-centric approach, where the synthesization controls are designed to adapt the data generation process to your business expectations;
- Tailored Privacy Control: Although both Fabric and SDV enable anonymization, Fabric’s Anonymization Engine allows the automatic detection of Personal Identifiable Information and also offers controls based on differential privacy and a flexible Privacy Layer, allowing users to define what type of trade-off to apply to the data.
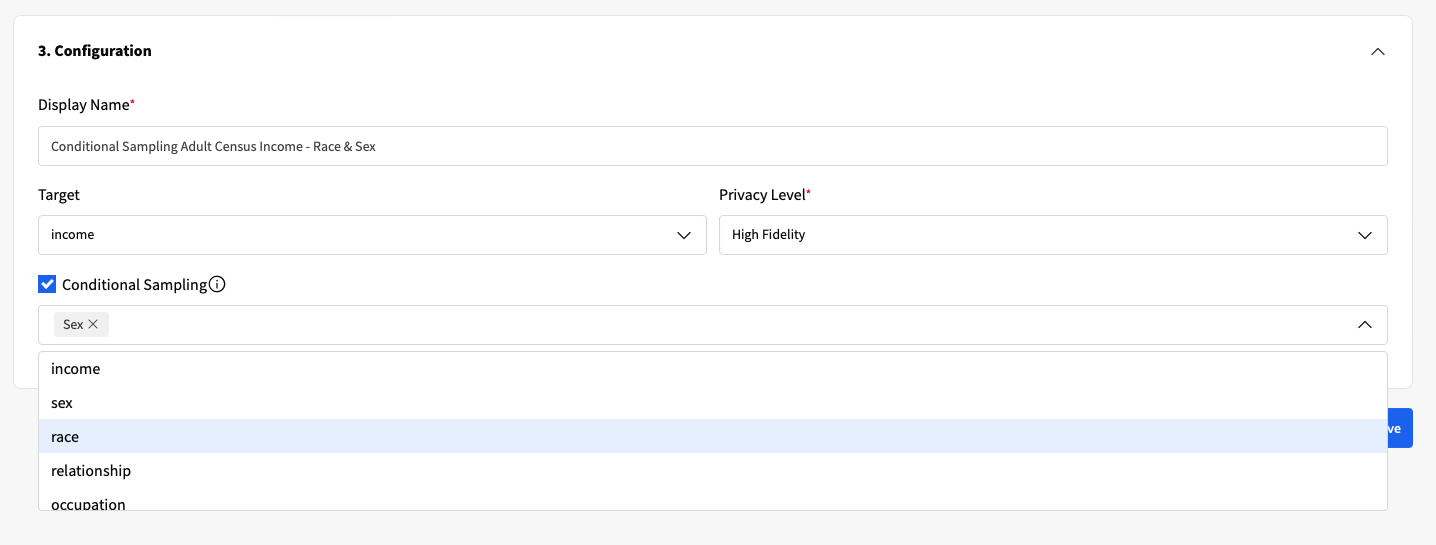
Synthetic Data Quality Evaluation
Comparing the synthetic data against the real data is a fundamental step in assessing the quality of the generated data.
- Flexible Data Quality Assessment: While both Fabric and SDV offer quality evaluation metrics and outputs for synthetic data, Fabric goes further by providing a Data Catalog with a more extensive set of features, including scalable visualizations and interactive profile comparisons. With the Data Quality Report, available in a standard PDF format, Fabric also makes it easier to evaluate data quality across distinct standards that are critical for organizations, namely fidelity, privacy, and utility;
- Iterative Comparison using Pipelines: Unlike SDV, Fabric offers more features beyond synthetic data, including model training and pipelines, which can enable the iterative improvement of the generation process until it meets the business expectations.
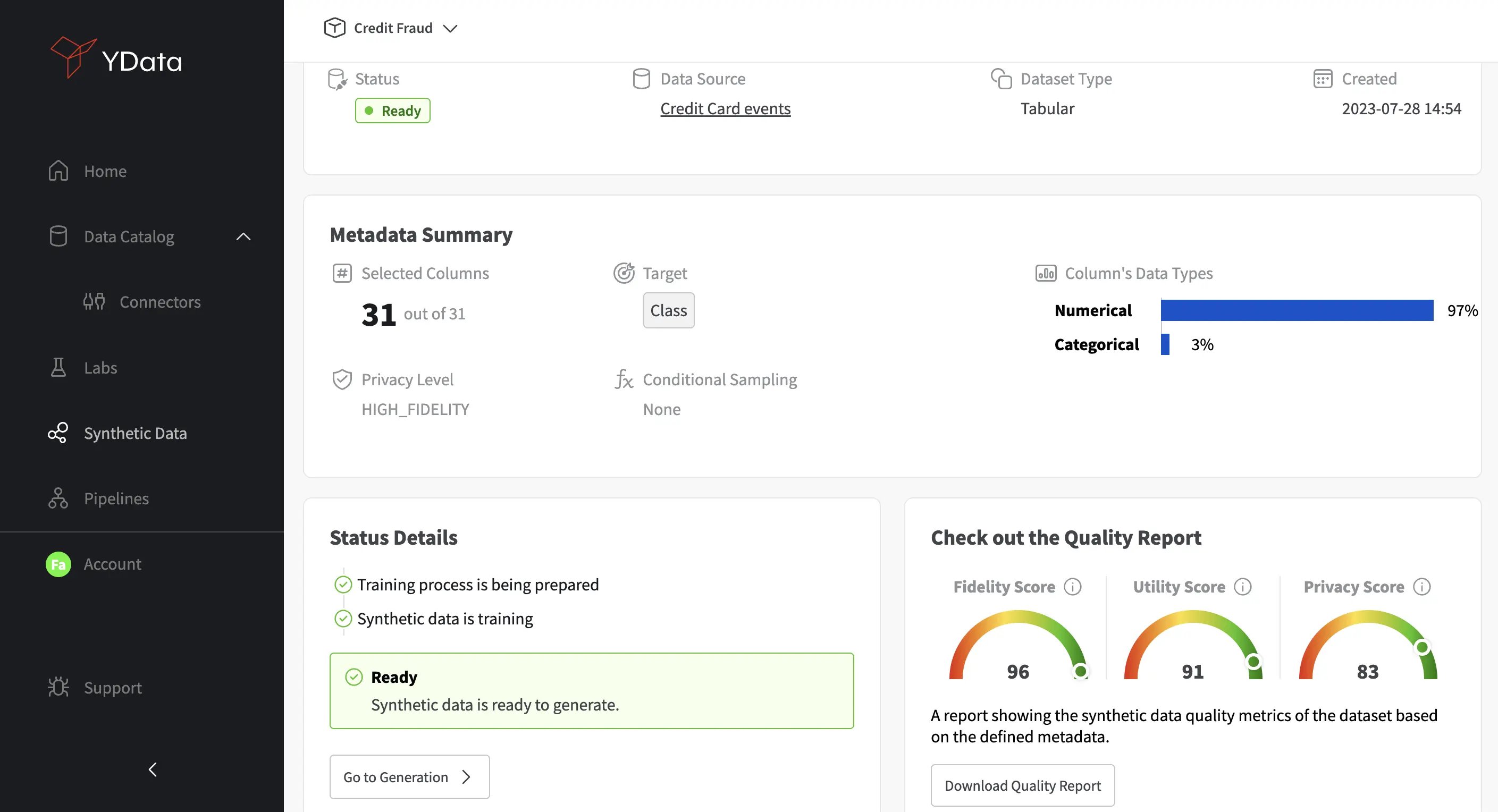
Scalability, Hardware Requirements, and Performance
Scale and performance are perhaps the factors that propel organizations to move towards proprietary software since open-source solutions simply can’t cope with the requirements of real-world data:
- High Scalability and Flexibility: Contrary to SDV, Fabric is a highly scalable platform, seamless, friendly, and transparent for the user, where the resource usage is automatically managed to produce rapid availability and responsiveness while keeping costs low;
- Patented Data Flow: Fabric can accommodate datasets of any size, ensuring adaptability to complex business domains. SDV has limited scalability and requires manual configuration and optimization.
- Superior Performance: In comparison to SDV, Fabric's synthetic data generation process has demonstrated superior results both in terms of synthetic data quality and performance, with much faster computation times as confirmed across this benchmark evaluation.
Additionally, while SDV provides only a Python SDK, Fabric enables multiple interfaces (a GUI, an API, and an SDK), and provides several integrations and ecosystems, supporting the most common cloud vendors, data engineering platforms, and popular data science IDEs.
Conclusion
Throughout this article, we discussed the similarities and differences between Fabric and SDV, highlighting the limitations that open-source solutions face when handling real-world scenarios where scalability, optimization, usability, and business-centric perspectives are non-negotiable.
If you’re looking to fully unlock your assets for data sharing or secure development initiatives for your organization, open-source solutions will not be able to cope with your specific business needs, data flow’s complexity, and scale.
Open-source solutions are great for exploring new technology’s benefits and limitations but might be more limited for production systems where reliability is part of the requirements. Fabric’s interfaces (GUI and code) enable different profiles within an organization to leverage the benefits of synthetic data, from data stewards and quality assurance engineers all the way to data analysts and data scientists.
In case you’re still on the fence, check it for yourself. You may find a complete benchmark comparing Fabric with SDV across several datasets, read up on a point-by-point comparison between Fabric and SDV across the components mentioned above.
When you’re ready to take your AI endeavors to the next level, take a look at Fabric and sign up for the community version, or contact us for trial access to the full platform.